FAQ #
[Driver] 使用 dbplus-engine driver 时报 Failed to get driver instance for jdbcUrl=… #
可能是由于没有加载到驱动的原因,需要注意驱动的 jar 包与 dbplus-engine 的 jar 包要放在同一个目录,也可以通过 -cp 参数来明确指定依赖驱动。
执行迁移时,目标端表时间类型的字段需要 not null, 如果为null时即 “0000-00-00 00:00:00” 在全量迁移阶段会报错,报错如下 #
com.mysql.jdbc.exceptions.jdbc4.MySQLIntegrityConstraintViolationException: Column 'c_timestamp' cannot be null
at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.base/java.lang.reflect.Constructor.newInstance(Constructor.java:490)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:403)
at com.mysql.jdbc.Util.getInstance(Util.java:386)
SphereEx-DBPlusEngine 1.5.0 版本中增加了 rule 的 properties 校验逻辑,如不匹配报错如下 #
mysql> CREATE ENCRYPT RULE t_order (COLUMNS((NAME=user_id,PLAIN=user_plain,CIPHER=user_cipher,ENCRYPT_ALGORITHM(TYPE(NAME='SM9',PROPERTIES('sm3-salt'='123456abc'))))),QUERY_WITH_CIPHER_COLUMN=true);
ERROR 30000 (HY000): Unknown exception: SPI-00001: No implementation class load from SPI `org.apache.shardingsphere.encrypt.spi.EncryptAlgorithm` with type `SM9`.
使用 Aurora 数据库+ Aurora JDBC URL + Aurora 驱动的情况下,未配置 proxy-frontend-database-protocol-type 参数(即使用默认值 MySQL)重启 Proxy 之后,无法再次登录 Proxy,报错:“ERROR 2013 (HY000): Lost connection to MySQL server at ‘reading initial communication packet’, system error: 2“ #
回答:
配置全局 props “proxy-frontend-database-protocol-type : Aurora ”参数 重启生效
不重启的情况下,需要在 ./zkCli.sh 下执行下面的语句
create /governance_ds2/props
set /governance_ds2/props 'proxy-frontend-database-protocol-type : Aurora'
SphereEx-DBPlusEngine-Proxy 在 AWS 上的收费标准? #
- AWS 的 BYOL
- AWS 的 pay-as-you-go (仅限 global )
具体报价请联系我们
如何在AWS上使用 SphereEx-DBPlusEngine-Proxy AMI 镜像? #
回答:
- dbplusengine 应用安装在 /opt/sphereex-dbplusengine-proxy 目录下
- dbplusengine 的 systemd 服务文件为 /usr/lib/systemd/system/dbplusengine-proxy.service
[Unit]
Description=SphereEx dbplusengine Service
Requires=network.target
After=network.target
[Service]
Type=forking
LimitNOFILE=65536
ExecStart=/opt/sphereex-dbplusengine-proxy/bin/start.sh
ExecStop=/opt/sphereex-dbplusengine-proxy/bin/stop.sh
Restart=always
RestartSec=5
StartLimitInterval=0
[Install]
WantedBy=default.target
运维
查看
systemctl status dbplusengine-proxy
启动
systemctl start dbplusengine-proxy
重启
systemctl restart dbplusengine-proxy
停止
systemctl stop dbplusengine-proxy
配置 JVM 内存
默认的 jvm 内存参数为 “ -Xmx2g -Xms2g -Xmn1g ”, 如果您想更改,可以按照如下部署:
- 修改 dbplusengine-proxy.service 配置, 在 Service 下添加如下配置
[Service]
...
Environment="JAVA_MEM_COMMON_OPTS=-Xmx512m -Xms512m -Xmn128m "
- 重载服务
systemctl daemon-reload
- 重启服务
systemctl restart dbplusengine-proxy
[Driver/Proxy] 为什么启动Proxy会报 Current instance version not allowed join the cluster? #
回答:
在1.3.0版本之后增加了集群版本校验功能,启动的计算节点时无法兼容集群版本时将无法启动。
[Proxy] MySQL 插入如下包含特殊字符的数据时,Engine-Proxy 会有报错 ERROR 1366 (HY000): Incorrect string value: ‘\xF0\x9F\x8E\x81wo…’ for column ‘origin’ at row 1 #
回答:
解决办法需要配置 Engine-Proxy 的链接串 或 MySQL server 的字符集
- 在 Engine-Proxy 的连接串上添加如下内容:
useUnicode=true&character_set_server=utf8mb4&connectionCollation=utf8mb4_unicode_ci
- 在线调整 MySQL server 参数
set @@character_set_server='utf8mb4';
set @@collation_server='utf8mb4_unicode_ci';
MySQL 的启动参数文件中添加如下两个配置项,重启后继续生效
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
[Driver] 为什么配置了某个数据连接池的 spring-boot-starter(比如 druid)和 shardingsphere-jdbc-spring-boot-starter 时,系统启动会报错? #
回答:
- 因为数据连接池的 starter(比如 druid)可能会先加载并且其创建一个默认数据源,这将会使得 DBPlusEngine-Driver 创建数据源时发生冲突。
- 解决办法为,去掉数据连接池的 starter 即可,DBPlusEngine-Driver 自己会创建数据连接池。
[Driver] 使用 Spring 命名空间时找不到 xsd? #
回答:
Spring 命名空间使用规范并未强制要求将 xsd 文件部署至公网地址,但考虑到部分用户的需求,我们也将相关 xsd 文件部署至 DBPlusEngine 官网。
实际上 shardingsphere-jdbc-spring-namespace 的 jar 包中 META-INF\spring.schemas 配置了 xsd 文件的位置:
META-INF\namespace\sharding.xsd 和 META-INF\namespace\replica-query.xsd,只需确保 jar 包中该文件存在即可。
[Driver] 引入 shardingsphere-transaction-xa-core 后,如何避免 spring-boot 自动加载默认的 JtaTransactionManager?
#
回答:
- 需要在 spring-boot 的引导类中添加
@SpringBootApplication(exclude = JtaAutoConfiguration.class)。
[Proxy] Windows 环境下,运行 DBPlusEngine-Proxy,找不到或无法加载主类 org.apache.shardingsphere.proxy.Bootstrap,如何解决? #
回答:
某些解压缩工具在解压 DBPlusEngine-Proxy 二进制包时可能将文件名截断,导致找不到某些类。
解决方案:
打开 cmd.exe 并执行下面的命令:
tar zxvf apache-shardingsphere-${RELEASE.VERSION}-shardingsphere-proxy-bin.tar.gz
[Proxy] 在使用 DBPlusEngine-Proxy 的时候,如何动态添加新的 logic schema? #
回答:
使用 DBPlusEngine-Proxy 时,可以通过 DistSQL 动态的创建或移除 logic schema,语法如下:
CREATE (DATABASE | SCHEMA) [IF NOT EXISTS] schemaName;
DROP (DATABASE | SCHEMA) [IF EXISTS] schemaName;
例:
CREATE DATABASE sharding_db;
DROP SCHEMA sharding_db;
[Proxy] 在使用 DBPlusEngine-Proxy 时,怎么使用合适的工具连接到 DBPlusEngine-Proxy? #
回答:
- DBPlusEngine-Proxy 可以看做是一个 database server,所以首选支持 SQL 命令连接和操作。
- 如果使用其他第三方数据库工具,可能由于不同工具的特定实现导致出现异常。
- 目前已测试的第三方数据库工具如下:
- Navicat:11.1.13、15.0.20。
- DataGrip:2020.1、2021.1(使用 IDEA/DataGrip 时打开
introspect using JDBC metadata选项)。 - WorkBench:8.0.25。
[Proxy] 使用 Navicat 等第三方数据库工具连接 DBPlusEngine-Proxy 时,如果 DBPlusEngine-Proxy 没有创建 Schema 或者没有添加 Resource,连接失败? #
回答:
- 第三方数据库工具在连接 DBPlusEngine-Proxy 时会发送一些 SQL 查询元数据,当 DBPlusEngine-Proxy 没有创建
schema或者没有添加resource时,DBPlusEngine-Proxy 无法执行 SQL。 - 推荐先创建
schema和resource之后再使用第三方数据库工具连接。 - 有关
resource的详情请参考。相关介绍
[分片] Cloud not resolve placeholder … in string value …异常的解决方法? #
回答:
行表达式标识符可以使用${...}或$->{...},但前者与Spring本身的属性文件占位符冲突,因此在Spring环境中使用行表达式标识符建议使用$->{...}。
[分片] inline 表达式返回结果为何出现浮点数? #
回答:
Java的整数相除结果是整数,但是对于 inline 表达式中的 Groovy 语法则不同,整数相除结果是浮点数。 想获得除法整数结果需要将 A/B 改为 A.intdiv(B)。
[分片] 如果只有部分数据库分库分表,是否需要将不分库分表的表也配置在分片规则中? #
回答:
不需要,DBPlusEngine 会自动识别。
[分片] 指定了泛型为 Long 的 SingleKeyTableShardingAlgorithm,遇到 ClassCastException: Integer can not cast to Long?
#
回答:
必须确保数据库表中该字段和分片算法该字段类型一致,如:数据库中该字段类型为 int(11),泛型所对应的分片类型应为 Integer,如果需要配置为 Long 类型,请确保数据库中该字段类型为 bigint。
[分片、PROXY] 实现 StandardShardingAlgorithm 自定义算法时,指定了 Comparable 的具体类型为 Long, 且数据库表中字段类型为 bigint,出现 ClassCastException: Integer can not cast to Long 异常。
#
回答:
实现 doSharding 方法时,不建议指定方法声明中 Comparable 具体的类型,而是在 doSharding 方法实现中对类型进行转换,可以参考 ModShardingAlgorithm#doSharding 方法
[分片] DBPlusEngine 提供的默认分布式自增主键策略为什么是不连续的,且尾数大多为偶数? #
回答:
DBPlusEngine 采用 snowflake 算法作为默认的分布式自增主键策略,用于保证分布式的情况下可以无中心化的生成不重复的自增序列。因此自增主键可以保证递增,但无法保证连续。
而 snowflake 算法的最后4位是在同一毫秒内的访问递增值。因此,如果毫秒内并发度不高,最后4位为零的几率则很大。因此并发度不高的应用生成偶数主键的几率会更高。
在 3.1.0 版本中,尾数大多为偶数的问题已彻底解决,参见:https://github.com/apache/shardingsphere/issues/1617
[分片] 如何在 inline 分表策略时,允许执行范围查询操作(BETWEEN AND、>、<、>=、<=)? #
回答:
- 需要使用 4.1.0 或更高版本。
- 调整以下配置项(需要注意的是,此时所有的范围查询将会使用广播的方式查询每一个分表):
- 4.x版本:
allow.range.query.with.inline.sharding设置为true即可(默认为false)。 - 5.x版本:在 InlineShardingStrategy 中将
allow-range-query-with-inline-sharding设置为 true 即可(默认为 false)。
[分片] 为什么我实现了 KeyGenerateAlgorithm 接口,也配置了 Type,但是自定义的分布式主键依然不生效?
#
回答:
Service Provider Interface (SPI) 是一种为了被第三方实现或扩展的 API,除了实现接口外,还需要在 META-INF/services 中创建对应文件来指定 SPI 的实现类,JVM 才会加载这些服务。
具体的 SPI 使用方式,请大家自行搜索。
与分布式主键 KeyGenerateAlgorithm 接口相同,其他 DBPlusEngine 的扩展功能也需要用相同的方式注入才能生效。
[分片] DBPlusEngine 除了支持自带的分布式自增主键之外,还能否支持原生的自增主键? #
回答:是的,可以支持。但原生自增主键有使用限制,即不能将原生自增主键同时作为分片键使用。
由于 DBPlusEngine 并不知晓数据库的表结构,而原生自增主键是不包含在原始 SQL 中内的,因此 DBPlusEngine 无法将该字段解析为分片字段。如自增主键非分片键,则无需关注,可正常返回;若自增主键同时作为分片键使用,DBPlusEngine 无法解析其分片值,导致 SQL 路由至多张表,从而影响应用的正确性。
而原生自增主键返回的前提条件是 INSERT SQL 必须最终路由至一张表,因此,面对返回多表的 INSERT SQL,自增主键则会返回零。
[数据加密] JPA 和 数据加密无法一起使用,如何解决? #
回答:
由于数据加密的 DDL 尚未开发完成,因此对于自动生成 DDL 语句的 JPA与 数据加密一起使用时,会导致 JPA 的实体类(Entity)无法同时满足 DDL 和 DML 的情况。
解决方案如下:
- 以需要加密的逻辑列名编写 JPA 的实体类(Entity)。
- 关闭 JPA 的 auto-ddl,如 auto-ddl=none。
- 手动建表,建表时应使用数据加密配置的
cipherColumn,plainColumn和assistedQueryColumn代替逻辑列。
[数据加密] DESC 一张加密表只能看到逻辑列,通过 Proxy 新增与加密列、明文列、衍生列重名的列时报错怎么回事? #
DESC t_user;
+-------------------+--------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------------------+--------------+------+-----+-------------------+-----------------------------+
| user_id | int(11) | NO | PRI | NULL | auto_increment |
| user_name | varchar(64) | NO | | NULL | |
+-------------------+--------------+------+-----+-------------------+-----------------------------+
8 rows in set (0.09 sec)
mysql> ALTER TABLE t_user ADD COLUMN user_id_cipher varchar(255) DEFAULT null;
ERROR 1060 (42S21): Duplicate column name 'user_id_cipher'
回答:
由于 Proxy 模拟的元数据只会展示逻辑列,表结构中会自动屏蔽加密列、衍生列等物理列,统一修饰为逻辑列展示。因此,通过 Proxy 执行 DDL 新增与加密列等物理列同名的列时,会执行失败。
[单表] Table or view %s does not exist. 异常如何解决?
#
回答:
在 DBPlusEngine 1.5.0 之前的版本,单表采用了自动加载的方式,这种方式在实际使用中存在诸多问题:
- 逻辑库中注册大量数据源后,自动加载的单表数量过多会导致 ShardingSphere-Proxy/JDBC 启动变慢;
- 用户通过 DistSQL 方式使用时,通过会按照:注册存储单元 -> 创建分片、加密、读写分离等规则 -> 创建表的顺序进行操作。由于单表自动加载机制的存在,会导致操作过程中多次访问数据库进行加载,并且在多个规则混合使用时会导致单表元数据的错乱;
- 自动加载全部数据源中的单表,用户无法排除不想被 ShardingSphere 管理的单表或废弃表。
为了解决以上问题,从 DBPlusEngine 1.5.0 版本开始,调整了单表的加载方式,用户需要通过 YAML 配置或者 DistSQL 的方式手动加载数据库中的单表。 需要注意的是,使用 DistSQL LOAD 语句加载单表时,需要保证所有数据源完成注册,所以规则创建完成后,再基于逻辑数据源(不存在逻辑数据源则使用物理数据源)进行单表 LOAD 操作。
- YAML 加载单表示例:
rules:
- !SINGLE
tables:
- "*.*"
- !READWRITE_SPLITTING
dataSources:
readwrite_ds:
writeDataSourceName: write_ds
readDataSourceNames:
- read_ds_0
- read_ds_1
loadBalancerName: random
loadBalancers:
random:
type: RANDOM
更多加载单表 YAML 配置请参考单表。
- DistSQL 加载单表示例:
LOAD SINGLE TABLE *.*;
更多 LOAD 单表 DistSQL 请参考单表加载。
[DistSQL] 使用 DistSQL 添加数据源时,如何设置自定义的 Driver 连接参数或连接池属性? #
回答:
- 如需自定义 Driver 参数,请使用
urlSource的方式定义dataSource。 - ShardingSphere预置了必要的连接池参数,如
maxPoolSize、idleTimeout等。如需增加或覆盖参数配置,请在dataSource中通过PROPERTIES指定。 - 以上规则请参考 相关介绍
[DistSQL] 使用 DistSQL 删除资源时,出现 Resource [xxx] is still used by [SingleTableRule]。
#
回答:
被规则引用的资源将无法被删除
若资源只被 single table rule 引用,且用户确认可以忽略该限制,则可以添加可选参数 ignore single tables 进行强制删除
[DistSQL] 使用 DistSQL 添加资源时,出现 Failed to get driver instance for jdbcURL=xxx。
#
回答:
DBPlusEngine-Proxy 在部署过程中没有添加 jdbc 驱动,需要将 jdbc 驱动放入 DBPlusEngine-Proxy 解压后的 ext-lib 目录,例如:mysql-connector。
[其他] 如果 SQL 在 DBPlusEngine 中执行不正确,该如何调试? #
回答:
在 DBPlusEngine-Proxy 以及 DBPlusEngine-Driver 1.5.0 版本之后提供了 sql.show 的配置,可以将解析上下文和改写后的 SQL 以及最终路由至的数据源的细节信息全部打印至 info 日志。
sql.show 配置默认关闭,如果需要请通过配置开启。
注意:5.x版本以后,
sql.show参数调整为sql-show。
[其他] 阅读源码时为什么会出现编译错误? IDEA 不索引生成的代码? #
回答:
DBPlusEngine 使用 lombok 实现极简代码。关于更多使用和安装细节,请参考lombok官网。
org.apache.shardingsphere.sql.parser.autogen 包下的代码由 ANTLR 生成,可以执行以下命令快速生成:
./mvnw -Dcheckstyle.skip=true -Drat.skip=true -Dmaven.javadoc.skip=true -Djacoco.skip=true -DskipITs -DskipTests install -T1C
生成的代码例如 org.apache.shardingsphere.sql.parser.autogen.PostgreSQLStatementParser 等 Java 文件由于较大,默认配置的 IDEA 可能不会索引该文件。
可以调整 IDEA 的属性:idea.max.intellisense.filesize=10000
[其他] 使用 SQLSever 和 PostgreSQL 时,聚合列不加别名会抛异常? #
回答:
SQLServer 和 PostgreSQL 获取不加别名的聚合列会改名。例如,如下SQL:
SELECT SUM(num), SUM(num2) FROM tablexxx;
SQLServer获取到的列为空字符串和(2),PostgreSQL获取到的列为空sum和sum(2)。这将导致ShardingSphere在结果归并时无法找到相应的列而出错。
正确的SQL写法应为:
SELECT SUM(num) AS sum_num, SUM(num2) AS sum_num2 FROM tablexxx;
[其他] Oracle 数据库使用 Timestamp 类型的 Order By 语句抛出异常提示 “Order by value must implements Comparable”? #
回答:
针对上面问题解决方式有两种: 1.配置启动 JVM 参数 “-oracle.jdbc.J2EE13Compliant=true” 2.通过代码在项目初始化时设置 System.getProperties().setProperty(“oracle.jdbc.J2EE13Compliant”, “true”);
原因如下:
org.apache.shardingsphere.sharding.merge.dql.orderby.OrderByValue#getOrderValues() 方法如下:
private List<Comparable<?>> getOrderValues() throws SQLException {
List<Comparable<?>> result = new ArrayList<>(orderByItems.size());
for (OrderItem each : orderByItems) {
Object value = resultSet.getObject(each.getIndex());
Preconditions.checkState(null == value || value instanceof Comparable, "Order by value must implements Comparable");
result.add((Comparable<?>) value);
}
return result;
}
使用了 resultSet.getObject(int index)方法,针对 TimeStamp oracle 会根据 oracle.jdbc.J2EE13Compliant 属性判断返回 java.sql.TimeStamp 还是自定义 oralce.sql.TIMESTAMP 详见 ojdbc 源码 oracle.jdbc.driver.TimestampAccessor#getObject(int var1) 方法:
Object getObject(int var1) throws SQLException {
Object var2 = null;
if(this.rowSpaceIndicator == null) {
DatabaseError.throwSqlException(21);
}
if(this.rowSpaceIndicator[this.indicatorIndex + var1] != -1) {
if(this.externalType != 0) {
switch(this.externalType) {
case 93:
return this.getTimestamp(var1);
default:
DatabaseError.throwSqlException(4);
return null;
}
}
if(this.statement.connection.j2ee13Compliant) {
var2 = this.getTimestamp(var1);
} else {
var2 = this.getTIMESTAMP(var1);
}
}
return var2;
}
[其他] Windows 环境下,通过 Git 克隆 DBPlusEngine 源码时为什么提示文件名过长,如何解决? #
回答:
为保证源码的可读性,DBPlusEngine 编码规范要求类、方法和变量的命名要做到顾名思义,避免使用缩写,因此可能导致部分源码文件命名较长。由于 Windows 版本的 Git 是使用 msys 编译的,它使用了旧版本的 Windows Api,限制文件名不能超过 260 个字符。
解决方案如下:
打开 cmd.exe(你需要将 git 添加到环境变量中)并执行下面的命令,可以让 git 支持长文件名:
git config --global core.longpaths true
如果是 Windows 10,还需要通过注册表或组策略,解除操作系统的文件名长度限制(需要重启):
在注册表编辑器中创建
HKLM\SYSTEM\CurrentControlSet\Control\FileSystem LongPathsEnabled, 类型为REG_DWORD,并设置为1。 或者从系统菜单点击设置图标,输入“编辑组策略”, 然后在打开的窗口依次进入“计算机管理” > “管理模板” > “系统” > “文件系统”,在右侧双击“启用 win32 长路径”。
参考资料: https://docs.microsoft.com/zh-cn/windows/desktop/FileIO/naming-a-file https://ourcodeworld.com/articles/read/109/how-to-solve-filename-too-long-error-in-git-powershell-and-github-application-for-windows
[其他] Type is required 异常的解决方法? #
回答:
DBPlusEngine 中很多功能实现类的加载方式是通过 SPI 注入的方式完成的,如分布式主键,注册中心等;这些功能通过配置中 type 类型来寻找对应的 SPI 实现,因此必须在配置文件中指定类型。
[其他] 服务启动时如何加快 metadata 加载速度?
#
回答:
- 升级到
4.0.1以上的版本,以提高 metadata 的加载速度。 - 参照你采用的连接池,将:
- 配置项
max.connections.size.per.query(默认值为1)调高(版本 >= 3.0.0.M3 且低于 5.0.0)。 - 配置项
max-connections-size-per-query(默认值为1)调高(版本 >= 5.0.0)。
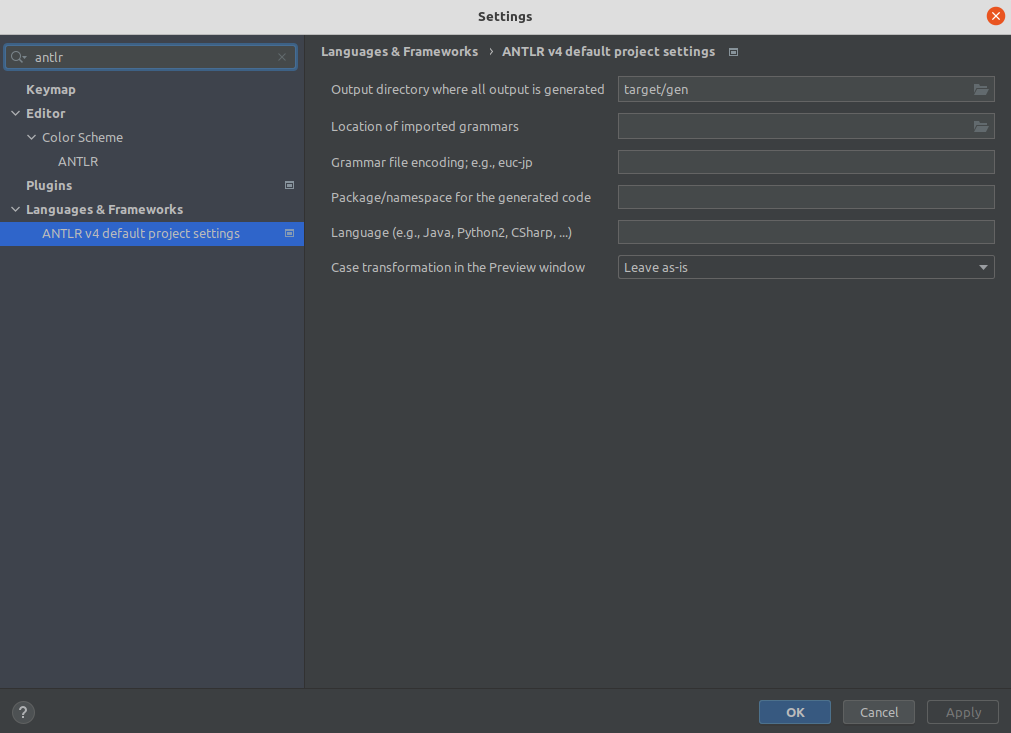
[其他] ANTLR 插件在 src 同级目录下生成代码,容易误提交,如何避免? #
回答:
进入 Settings -> Languages & Frameworks -> ANTLR v4 default project settings 配置生成代码的输出目录为 target/gen,如图:
[其他] 使用 Proxool 时分库结果不正确?
#
回答:
使用 Proxool 配置多个数据源时,应该为每个数据源设置 alias,因为 Proxool 在获取连接时会判断连接池中是否包含已存在的 alias,不配置 alias 会造成每次都只从一个数据源中获取连接。
以下是 Proxool 源码中 ProxoolDataSource 类 getConnection 方法的关键代码:
if(!ConnectionPoolManager.getInstance().isPoolExists(this.alias)) {
this.registerPool();
}
更多关于 alias 使用方法请参考 Proxool官网。
PS:sourceforge 网站需要翻墙访问。
[其他] 使用 Spring Boot 2.x 集成 DBPlusEngine 时,配置文件中的属性设置不生效? #
回答:
需要特别注意,Spring Boot 2.x 环境下配置文件的属性名称约束为仅允许小写字母、数字和短横线,即[a-z][0-9]和-。
原因如下:
Spring Boot 2.x 环境下,DBPlusEngine 通过 Binder 来绑定配置文件,属性名称不规范(如:驼峰或下划线等)会导致属性设置不生效从而校验属性值时抛出 NullPointerException 异常。参考以下错误示例:
下划线示例:database_inline
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.props.algorithm-expression=ds-$->{user_id % 2}
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'database_inline': Initialization of bean failed; nested exception is java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
...
Caused by: java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
at com.google.common.base.Preconditions.checkNotNull(Preconditions.java:897)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.getAlgorithmExpression(InlineShardingAlgorithm.java:58)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.init(InlineShardingAlgorithm.java:52)
at org.apache.shardingsphere.spring.boot.registry.AbstractAlgorithmProvidedBeanRegistry.postProcessAfterInitialization(AbstractAlgorithmProvidedBeanRegistry.java:98)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsAfterInitialization(AbstractAutowireCapableBeanFactory.java:431)
...
驼峰示例:databaseInline
spring.shardingsphere.rules.sharding.sharding-algorithms.databaseInline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.databaseInline.props.algorithm-expression=ds-$->{user_id % 2}
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'databaseInline': Initialization of bean failed; nested exception is java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
...
Caused by: java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
at com.google.common.base.Preconditions.checkNotNull(Preconditions.java:897)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.getAlgorithmExpression(InlineShardingAlgorithm.java:58)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.init(InlineShardingAlgorithm.java:52)
at org.apache.shardingsphere.spring.boot.registry.AbstractAlgorithmProvidedBeanRegistry.postProcessAfterInitialization(AbstractAlgorithmProvidedBeanRegistry.java:98)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsAfterInitialization(AbstractAutowireCapableBeanFactory.java:431)
...
从异常堆栈中分析可知: AbstractAlgorithmProvidedBeanRegistry.registerBean 方法调用 PropertyUtil.containPropertyPrefix(environment, prefix) 方法判断指定前缀 prefix 的配置是否存在,而 PropertyUtil.containPropertyPrefix(environment, prefix) 方法,在 Spring Boot 2.x 环境下使用了 Binder,不规范的属性名称(如:驼峰或下划线等)会导致属性设置不生效。
[Proxy] Proxy无法启动,报错:java.sql.SQLException: Unknown system variable 'transaction_isolation'
#
回答:
问题是由于数据库版本与驱动版本不一致导致的。举例来说,Proxy通过mysql-connector(5.1.49版本)访问MySQL(5.7.12版本)时出现了错误。
transaction_isolation 这个变量是在MySQL 5.7.20 版本中作为 tx_isolation 的别名引入的,而 5.7.12 版本并不支持这个变量。此外,MySQL Connector 从 5.1.44 版本开始支持 transaction_isolation 这个关键字。因此,使用 5.1.44 以上版本的驱动时,如果传入 transaction_isolation 就会报错。
[Proxy] 在使用 Proxy 后,无法向设置为 not null 的字段写入 null 值 #
回答:
MySQL 的 connector 默认设置了 SQL_MODE,在向 not null 字段写入 null 值时出现错误 Error 1364: Field 'message' doesn't have a default value。
创建 JDBC 连接时,在参数中加入 &jdbcCompliantTruncation=false,以防止 SET sql_mode 导致的问题,避免这种情况。
[事务] MySQL 8.0.28 版本驱动 Local 事务无法回滚 #
回答:
官方 Release 文档说明:https://dev.mysql.com/doc/relnotes/connector-j/8.0/en/news-8-0-29.html,记录了 8.0.28 版本在开启 useLocalSessionState 时,会出现 autoCommit 状态异常问题。
[Proxy] 字符乱码 java.sql.SQLException: Incorrect string value
#
回答:
数据通过直连 MySQL 可以成功插入,但通过 Engine-Proxy 连接无法成功,报错提示字符集不正确 java.sql.SQLException: Incorrect string value: '\xF0\x9F\x98\x89 (...' for column 'xxx' at row 1,
原因是字符集设置不一致导致插入特殊字符时出现编码问题。
确认 MySQL 和 Engine-Proxy 的字符集配置,确保它们匹配并正确设置为 utf8mb4。
在 MySQL 启动配置中添加 --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci。
在 Engine 的连接 URL 中添加参数 useUnicode=true&character_set_server=utf8mb4&connectionCollation=utf8mb4_unicode_ci。
相关 issue: https://github.com/apache/shardingsphere/issues/13023
[Driver] No suitable driver #
回答:
Spring 集成 Engine 系统启动时遇到如下报错: Failed to get driver instance for jdbcUrl=jdbc:h2:mem:config;DB_CLOSE_DELAY=-1;DATABASE_TO_UPPER=false;MODE=MYSQL
可以通过配置 bean 的方式加载驱动类:
<bean id="h2Driver" class="org.h2.Driver" />
<bean id="yourDataSource" depends-on="h2Driver">
或配置 driverClassName 绕过 DriverManager 加载的逻辑
相关 issue: https://github.com/apache/shardingsphere/issues/23768
[其他] Engine 查询得到的时间和通过 MySQL 直接查到的时间有差异。 #
回答:
spring/springboot 等程序连接的时候,jdbcUrl 带上时区,确保客户端,proxy,数据库时区完全保持一致,比如 jdbc:mysql://localhost:3306/test?serverTimezone=Asia/Shanghai
[Driver] java.lang.IllegalStateException: PathVariable annotation was empty on param 0.
#
回答:
业务应用启动时,Spring 报 @PathVariable 相关错误。 业务应用使用 Ant 构建项目时,确保 javac 使用了参数 -parameter。
Ant 增加编译参数示例:
<javac>
<compilerarg line="-parameter" />
</javac>
[其他] java.sql.SQLException: Connection is read-only.
#
回答:
在应用的启动过程中遇到了如下报错:Caused by: java.sql.SQLException: Connection is read-only. Queries leading to data modification are not allowed
- 数据库是否添加了 read-only 的配置,通过 show global variables like “%read_only%”; 查询
- 代码中是否手动将事务改为 readOnly,全局搜索代码是否包含 @Transactional (readOnly = true)
[其他] Socket is closed 或者 Connection timed out
#
回答:
原因:
- 连接长时间没有数据包传输,且 ack 被防火墙阻挡导致连接超时。
- 可能由于网络问题或者防火墙设置导致 keep-alive 失败,进而触发了连接超时和关闭。
- JDBC 驱动未设置 socketTimeout,导致在尝试读取时连接已经超时。
解决:
- 调整网络参数,例如 tcp_keepalive_time、tcp_keepalive_probes 和 tcp_keepalive_intvl,以确保连接保持活跃。
- 检查并配置 JDBC 驱动的 socketTimeout 参数,以避免长时间无操作导致的超时。
- 检查防火墙设置,确保它不会阻止心跳包或长时间空闲的连接。
- 监控链接池和进程列表,以识别并解决长时间无操作的问题。
[其他] MySQL ERROR 1118 (42000): Row size too large
#
回答:
问题原因
- MySQL 对每个表有 4096 列数量的限制, innodb 一个表最多可以包含 1017 列;
- MySQL Server 本身对一行所有字段的长度有 65,535 字节的最大行大小限制。即使存储引擎能够支持更大的行,MySQL 表的内部表示也具有 65,535 字节的最大行大小限制。 BLOB 和 TEXT 列仅对行大小限制贡献 9 到 12 个字节,因为它们的内容与行的其余部分分开存储。
- InnoDB 表的最大行大小(适用于数据库页中本地存储的数据)对于 4KB、8KB、16KB 和 32KB innodb_page_size 设置来说略小于半页。例如,对于默认的 16KB InnoDB 页面大小,最大行大小略小于 8KB。对于 64KB 页面,最大行大小略小于 16KB。
报错1的原因就是对应上面的第二点,MySQL Server 本身对一行所有字段的长度有 65,535 字节的最大行大小限制。BLOB 和 TEXT 不算。
报错2的原因就是对应上面的第三点,innodb 默认页大小为 16 KB,所有行的长度不能超过 innodb_page_size 半页,也就是默认 8KB(8192),就是上面报错信息里的 8126。
问题解决
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
修改现有表结构为 text。
修改为text之后,报错2如下:
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 8126. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
报错2解决如下:
方式1:
show variables like '%innodb_strict_mode%';
set session innodb_strict_mode = 0;
方式2:
调大 innodb_page_size 参数。
[Proxy] Caused by: java.sql.SQLException: Error retrieving record: Unexpected Exception: java.io.EOFException message given: Can not read response from server. Expected to read 311 bytes, read 110 bytes before connection was unexpectedly lost.
#
回答:
原因:
由于连接数量、数据量较大,部分连接的 streaming query 由于 Proxy 尚未来得及消费,连接 I/O 超时,MySQL 服务端主动断开超时连接。
解决:
方式1: jdbc url 添加 netTimeoutForStreamingResults
方式2:适当调大 MySQL 参数:
- net_write_timeout 默认 60 秒 https://dev.mysql.com/doc/refman/8.0/en/server-system-variables.html#sysvar_net_write_timeout
- net_read_timeout 默认 30 秒 https://dev.mysql.com/doc/refman/8.0/en/server-system-variables.html#sysvar_net_read_timeout
[Proxy] 查询中文乱码 #
回答:
用户应用通过 jdbc 连接 proxy 查询数据,出现中文乱码,且 jdbcUrl 设置 characterEncoding 后无效。最终定位到是 mysql 驱动版本太老存在 bug,更新应用侧 mysql 驱动版本解决问题。 问题版本:mysql-connector-java:5.0.8 更新版本:mysql-connector-java:5.1.47
[数据加密] PipelineJobPrepareFailedException: Source data source is lack of REPLICATION SLAVE
#
EncryptingJobScheduler - job prepare failed, 0230317c30327c317c61637469766974797c62616b5f62696c6c696e67735f3230323231303134-0
org.apache.shardingsphere.data.pipeline.core.exception.PipelineJobPrepareFailedException: Source data source is lack of REPLICATION SLAVE, REPLICATION CLIENT ON *.* privileges.
at org.apache.shardingsphere.data.pipeline.mysql.check.datasource.MysQLDataSourceChecker.checkPrivilege(MySQLDataSourceChecker.java:76)
at org.apache.shardingsphere.data.pipeline.mysql.check.datasource.MysQLDataSourceChecker.checkPrivilege(MySQLDataSourceChecker.java:58)
at org.apache.shardingsphere.data-pipeline.scenario.encrypting.EncryptingJobPreparer.checkSourceDataSource(EncryptingJobPreparer.java:150)
at org.apache.shardingsphere.data.pipeline.scenario.encrypting.EncryptingJobPreparer.prepare(EncryptingJobPreparer.java:50)
这个错误信息指出,在准备加密作业时失败了,原因是源数据源缺少REPLICATION SLAVE和REPLICATION CLIENT的权限。具体是在MysQLDataSourceChecker类中检查权限时发现问题,并在EncryptingJobPreparer类中准备作业时触发了异常。
解决:增加 MySQL 洗数相关权限
[元数据] ZooKeeper 挂掉是否影响 Engine 业务 #
回答:
- 首先,Zookeeper 的可用性设计得比较高,它通常具备自我恢复的能力,因此它挂掉的情况较少见。
- 其次,即使 Zookeeper 服务不可用,Engine 会在内存中保留一份配置的副本。这意味着只要 Engine 的引擎不重启,即使 Zookeeper 服务出现问题,Engine 仍然可以继续提供服务。
- 配置保留:如果 Zookeeper (zk) 服务不可用,Engine 的配置仍然保留在内存中。这意味着,只要不重启 DBPlusEngine,配置信息仍然可用。
- 高可用性:Zookeeper 通常部署为 3、5 或 7 节点的集群,具有很高的可用性。如果整个 Zookeeper 集群都出现问题,这通常意味着机房可能发生了重大故障,此时业务服务可能也无法正常提供。
- 业务连续性:即使 Zookeeper 出现集群级别的故障,DBPlusEngine 仍然可以继续提供服务,因为相关的规则和元数据信息已经缓存在每个 DBPlusEngine 的内存中。
- 避免配置修改:在 Zookeeper 修复之前,应避免修改任何配置,以防止配置不一致的情况发生。
[DistSQL] DistSQL 执行速度慢 #
回答:
分别检查了监控与日志,proxy 没有问题,但是访问 zk 比较频繁。
通过日志,确认了网络连通性出现了问题
[WARN ] 2022-10-31 07:47:21.015 [main-SendThread(172.20.116.158:2181)] org.apache.zookeeper.ClientCnxn - Session 0x0 for sever ip-172-20-116-158.us-west-2.compute.internal/172.20.116.158:2181, Closing socket connection. Attempting reconnect except it is a SessionExpiredException.
java.net.NoRouteToHostException: No route to host
[Pipeline] 迁移表的主键有什么约束吗 #
主键字段有如下约束:
- 必须是单字段主键
- 只支持整型或字符串类型
这一块后面会兼容更多的场景
[分片] 分片键的主键有什么限制 #
回答:
- 一般为字符串或者数字,需要全局唯一
- 基本都通过分布式主键生成器生成
- 支持 varbinary 类型,也可以通过复合分片算法支持多主键
[事务] MySQL @Transactional(readOnly=true) 注解的查询接口在开启 XA 事务后报错 #
回答:
- 问题:客户项目中所有使用@Transactional(readOnly=true)注解的查询接口在开启XA事务后报错,而使用本地事务时正常。
- 原因:经调试确认,异常由 XA END SQL 语句引起。客户环境的驱动逻辑错误地将非以"S"开头的SQL语句判断为非只读语句。此外,使用的是存在Bug的旧版本MySQL Connector/J(版本8.0.19)。
- 解决:建议客户升级至MySQL Connector/J的版本8.0.31,以解决这个问题。
[事务] Atomikos 事务数量上限异常 #
回答:
[ERROR] 2023-03-23 13:44:04.492 [Connection-2236870-ThreadExecutor] o.a.s.p.f.c.CommandExecutorTask - Exception occur:
java.lang.IllegalStateException: Max number of active transactions reached:10000
at com.atomikos.icatch.imp.TransactionServiceImp.createCompositeTransaction(TransactionServiceImp.java:633)
at com.atomikos.icatch.imp.CompositeTransactionManagerImp.createCompositeTransaction(CompositeTransactionManagerImp.java:399)
at com.atomikos.icatch.jta.TransactionManagerImp.begin(TransactionManagerImp.java:266)
at com.atomikos.icatch.jta.TransactionManagerImp.begin(TransactionManagerImp.java:244)
at com.atomikos.icatch.jta.UserTransactionManager.begin(UserTransactionManager.java:133)
at org.apache.shardingsphere.transaction.xa.XAShardingSphereTransactionManager.begin(XAShardingSphereTransactionManager.java:98)
解决方案:创建配置文件 jta.properties 并指定 com.atomikos.icatch.max_actives=-1。
[事务] com.mysql.cj.jdbc.MysqlXAException: XAER_RMERR: Fatal error occurred in the transaction branch - check your data for consistency
#
回答:
账号缺少系统权限。
[Driver] SpringBoot 启动报 SnakeYAML 相关错误 #
回答:
springboot 2.x 引入的 SnakeYAML 版本过低,需要手动引入 1.33 版本的 SnakeYAML。
[Driver] 使用 driver-all-in-one jar 包启动出现 NoClassDefFoundError: Could not initialize class xxx.ConfigurationPropertyKey #
回答:
ConfigurationPropertyKey 中包含了日志级别设置属性,需要依赖 SLF4J 中的 Level 枚举类,如果 SLF4J 版本过低,会出现 NoClassDefFoundError 异常,建议使用 1.7.36 及之后版本。
[Pipeline] 如何合理的设置洗数规则 #
需要注意在无唯一键洗数场景下,只有 READ BATCH_SIZE 参数有效
ALTER ENCRYPTING RULE (
READ(
WORKER_THREAD=20,
BATCH_SIZE=1000,
SHARDING_SIZE=10000000,
RATE_LIMITER (TYPE(NAME='QPS',PROPERTIES('qps'='500')))
),
WRITE(
WORKER_THREAD=20,
BATCH_SIZE=1000,
RATE_LIMITER (TYPE(NAME='TPS',PROPERTIES('tps'='2000')))
),
STREAM_CHANNEL (TYPE(NAME='MEMORY',PROPERTIES('block-queue-size'='2000')))
);
Ucpu = CPU 使用率,Ncpu = CPU 数量,Rows = 数据库表行数,Umem = 内存使用大小,avg_size = 平均字段值大小
WORKER_THREAD = 2 * Ncpu x Ucpu (经验值 需要根据实际情况调整)
SHARDING_SIZE <= Rows / WORKER_THREAD
BATCH_SIZE 最佳大小受到多种因素影响,如数据库性能、网络情况等,一般建议设置为 1000,block-queue-size 设置为其两倍
Umem >= WORKER_THREAD * (block-queue-size + 2 * BATCH_SIZE) * (1KB + avg_size) (还有其他如洗数线程、JDBC 内存占用等)
[元数据] Oracle 数据库报错 不支持的字符集 (在类路径中添加 orai18n.jar): ZHS16GBK
#
增加对应版本的 Oracle 的字符集支持包 orai18n.jar 到类路径中。
[联邦查询] 使用 JDK 22 运行联邦查询出现阻塞问题 #
由于联邦查询内部使用了 jol-core 库,而该库在 JDK 22 中存在兼容性问题,导致联邦查询在 JDK 22 环境下运行时出现阻塞。因此,使用联邦查询时,建议使用 JDK 8、JDK 11、JDK 17、JDK 21 等长期支持版本,以确保其稳定性和兼容性。