分组 #
原理 #
DBPlusEngine 分组功能可以分为流式分组和内存分组,流式分组是指通过流式查询的方式,逐条将数据加载至内存进行分组计算,流式分组要求 SQL 的排序项与分组项的字段以及排序类型(ASC 或 DESC)必须保持一致。内存分组是指将查询结果集一次加载至内存,然后在内存中进行分组计算,内存分组适用于 SQL 排序项与分组项的字段及排序类型(ASC 或 DESC)无法保持一致的场景,内存分组会占用更多内存。
建议 #
保证 SQL 的排序项与分组项的字段以及排序类型(ASC 或 DESC)一致,以使用流式分组,减少内存消耗;
说明:若按AB进行排序,按BA做分组或排序,不可使用到流式处理,因为字段不一致。
示例 #
以如下 SQL 为例:
SELECT name, SUM(score) FROM t_score GROUP BY name ORDER BY name;
假设根据科目分片,表结构中包含考生的姓名(为了简单起见,不考虑重名的情况)和分数,通过这个 SQL 我们可以获取每位考生的总分。
在分组项与排序项完全一致的情况下,取得的数据是连续的,分组所需的数据全数存在于各个数据结果集的当前游标所指向的数据值,因此可以采用流式归并。如下图所示。
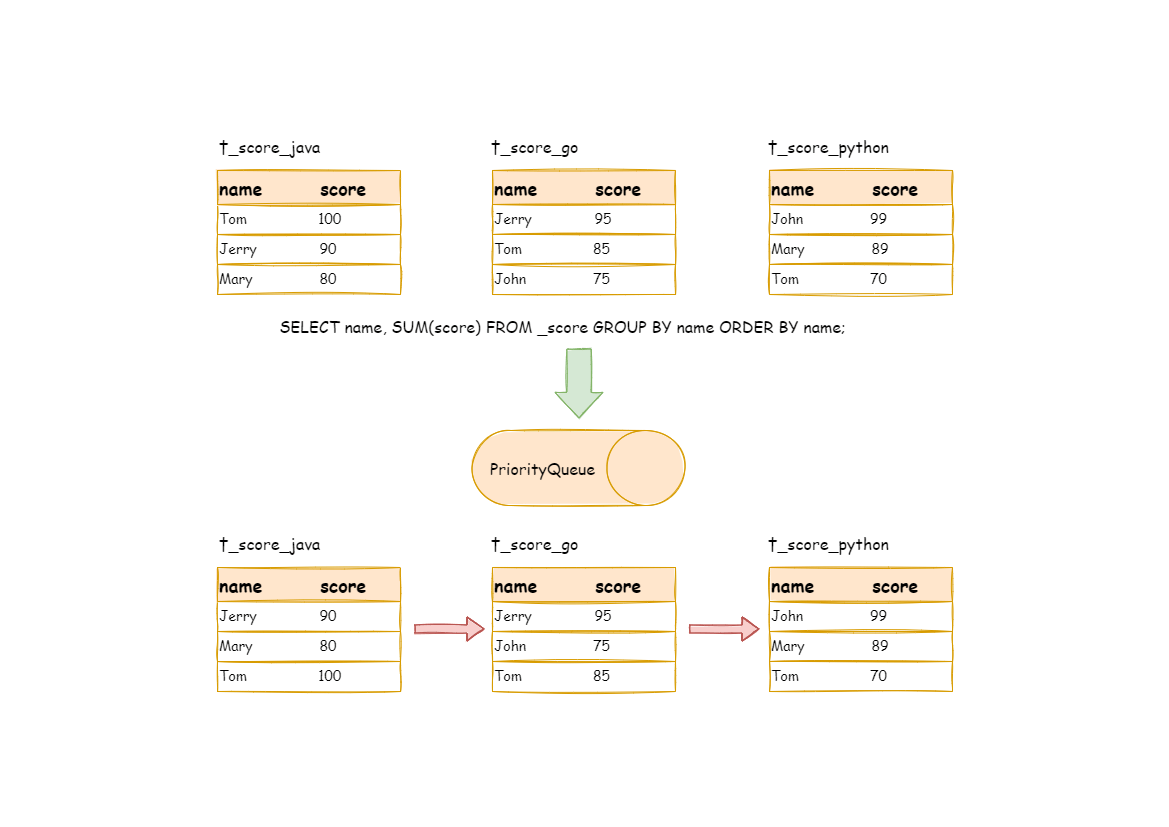
DBPlusEngine 进行归并处理时,逻辑与排序归并类似。下图展现了进行 next 调用的时候,流式分组归并是如何进行的。
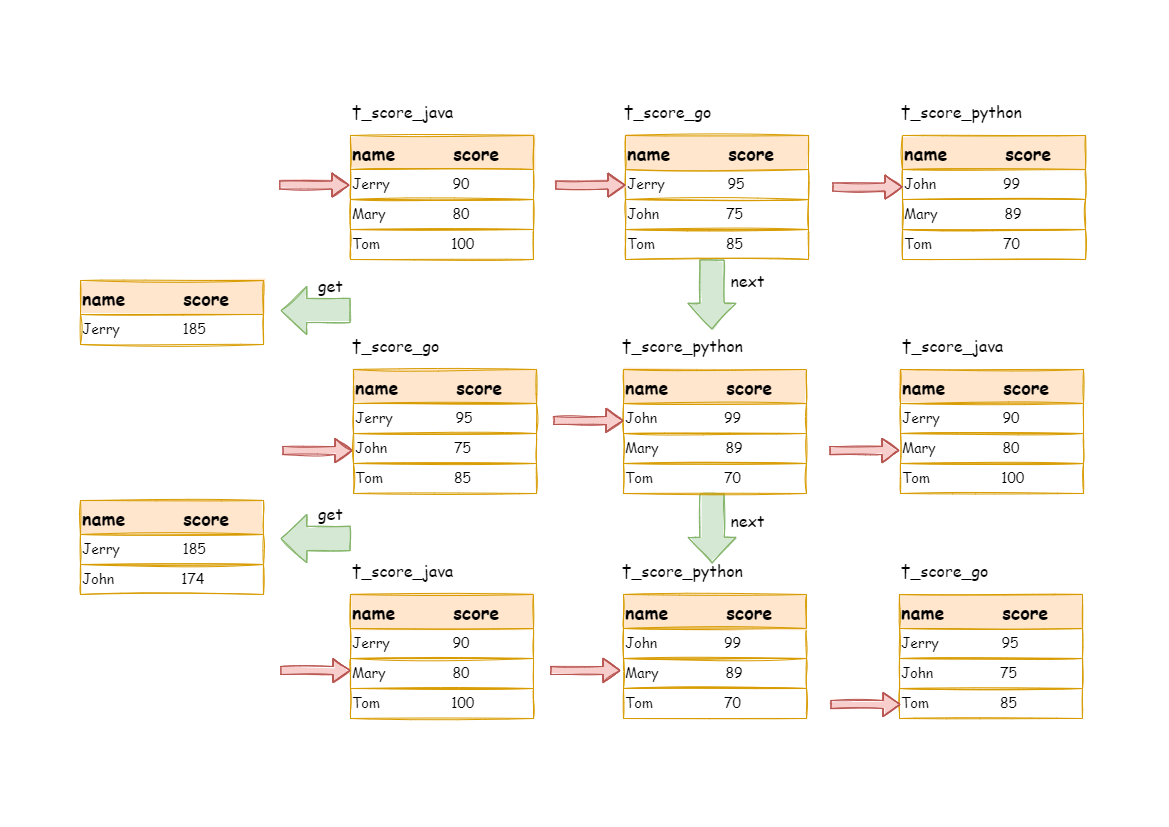
通过图中我们可以看到,当进行第一次 next 调用时,排在队列首位的 t_score_java 将会被弹出队列,并且将分组值同为 “Jerry” 的其他结果集中的数据一同弹出队列。 在获取了所有的姓名为 “Jerry” 的同学的分数之后,进行累加操作,那么,在第一次 next 调用结束后,取出的结果集是 “Jerry” 的分数总和。 与此同时,所有的数据结果集中的游标都将下移至数据值 “Jerry” 的下一个不同的数据值,并且根据数据结果集当前游标指向的值进行重排序。 因此,包含名字顺着第二位的 “John” 的相关数据结果集则排在的队列的前列。
对于分组项与排序项不一致的情况,由于需要获取分组的相关的数据值并非连续的,因此无法使用流式归并,需要将所有的结果集数据加载至内存中进行分组和聚合。 例如,若通过以下 SQL 获取每位考生的总分并按照分数从高至低排序:
SELECT name, SUM(score) FROM t_score GROUP BY name ORDER BY score DESC;
那么各个数据结果集中取出的数据与排序归并那张图的上半部分的表结构的原始数据一致,是无法进行流式归并的。
当 SQL 中只包含分组语句时,根据不同数据库的实现,其排序的顺序不一定与分组顺序一致。 但由于排序语句的缺失,则表示此 SQL 并不在意排序顺序。 因此,DBPlusEngine 通过 SQL 优化的改写,自动增加与分组项一致的排序项,使其能够从消耗内存的内存分组归并方式转化为流式分组归并方案。