FAQ #
During migration, the target table’s datetime fields must be marked as not null. If they contain null values or “0000-00-00 00:00:00” during the full migration phase, an error will occur, and the error message will be as follows: #
com.mysql.jdbc.exceptions.jdbc4.MySQLIntegrityConstraintViolationException: Column 'c_timestamp' cannot be null
at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.base/java.lang.reflect.Constructor.newInstance(Constructor.java:490)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:403)
at com.mysql.jdbc.Util.getInstance(Util.java:386)
In SphereEx-DBPlusEngine version 1.5.0, a validation logic for rule properties has been added. If they do not match, an error will be reported as follows: #
mysql> CREATE ENCRYPT RULE t_order (COLUMNS((NAME=user_id,PLAIN=user_plain,CIPHER=user_cipher,ENCRYPT_ALGORITHM(TYPE(NAME='SM9',PROPERTIES('sm3-salt'='123456abc'))))),QUERY_WITH_CIPHER_COLUMN=true);
ERROR 30000 (HY000): Unknown exception: SPI-00001: No implementation class load from SPI `org.apache.shardingsphere.encrypt.spi.EncryptAlgorithm` with type `SM9`.
How to use an SphereEx-DBPlusEngine-Proxy AMI image on AWS? #
Answer:
- The DBPlusEngine application is installed in the /opt/sphereex-dbplusengine-proxy directory.
- The systemd service file for DBPlusEngine is /usr/lib/systemd/system/dbplusengine-proxy.service
[Unit]
Description=SphereEx dbplusengine Service
Requires=network.target
After=network.target
[Service]
Type=forking
LimitNOFILE=65536
ExecStart=/opt/sphereex-dbplusengine-proxy/bin/start.sh
ExecStop=/opt/sphereex-dbplusengine-proxy/bin/stop.sh
Restart=always
RestartSec=5
StartLimitInterval=0
[Install]
WantedBy=default.target
Operation & Maintenance
View
systemctl status dbplusengine-proxy
Start
systemctl start dbplusengine-proxy
Restart
systemctl restart dbplusengine-proxy
Stop
systemctl stop dbplusengine-proxy
Configuring JVM memory
The default jvm memory parameter is " -Xmx2g -Xms2g -Xmn1g". If you want to change it, you can deploy it as follows.
- Modify the dbplusengine-proxy.service configuration and add the following configuration under Service
[Service]
...
Environment="JAVA_MEM_COMMON_OPTS=-Xmx512m -Xms512m -Xmn128m "
- Reload Service
systemctl daemon-reload
- Restart Service
systemctl restart dbplusengine-proxy
[Driver/Proxy] Why starting the Proxy report for the Current instance version not allowed to join the cluster? #
Answer:
After version 1.3.0, the cluster version check function has been added. If a compute node that is started is not compatible with the cluster version, it will not start.
[Proxy] Engine-Proxy gives an error when inserting data containing special characters as follows ERROR 1366 (HY000): Incorrect string value: ‘\xF0\x9F\x8E\x81wo… ’ for column ‘origin’ at row 1 #
Answer:
The solution requires configuring the link string of the Engine-Proxy or the character set of the MySQL server
- Add the following to the Engine-Proxy’s link string:
useUnicode=true&character_set_server=utf8mb4&connectionCollation=utf8mb4_unicode_ci
- Adjust MySQL server parameters online
set @@character_set_server='utf8mb4';
set @@collation_server='utf8mb4_unicode_ci';
Add the following two configuration items to MySQL’s startup parameters file to continue to take effect after reboot
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
[Driver] Why does the system start with an error when configuring spring-boot-starter (e.g. druid) and shardingsphere-jdbc-spring-boot-starter for a particular data connection pool? #
Answer:
- Because the starter of the data connection pool (e.g. druid) may be loaded first and it creates a default data source, this will cause a conflict when DBPlusEngine-Driver creates the data source.
- The solution is to remove the starter from the data connection pool and DBPlus Engine-Driver will create the data connection pool itself.
[Driver] Can’t find xsd when using Spring namespace? #
Answer:
The Spring namespace usage specification does not mandate that xsd files be deployed to a public address, but given the needs of some users, we have also deployed the relevant xsd files to the DBPlusEngine official site.
In fact, the META-INF\spring.schemas jar package for shardingsphere-jdbc-spring-namespace configures the location of the xsd files:
META-INF\namespace\sharding.xsd and META-INF\namespace \replica-query.xsd, just make sure the file exists in the jar package.
[Driver] How to avoid spring-boot automatically loading the default JtaTransactionManager after introducing shardingsphere-transaction-xa-core?
#
Answer:
- You need to add
@SpringBootApplication(exclude = JtaAutoConfiguration.class)to the bootstrap class of spring-boot.
[Proxy] While running DBPlusEngine-Proxy on Windows, I cannot find or load the main class org.apache.shardingsphere.proxy. How to fix this? #
Answer:
Some unzip tools may truncate the filename when extracting the DBPlusEngine-Proxy binary package, resulting in some classes not being found.
Solution:
Open cmd.exe and execute the following command:
tar zxvf apache-shardingsphere-${RELEASE.VERSION}-shardingsphere-proxy-bin.tar.gz
[Proxy] How to dynamically add a new logic schema when using DBPlusEngine-Proxy? #
Answer:
When using DBPlusEngine-Proxy, logic schema can be created or removed dynamically via DistSQL, with the following syntax:
CREATE (DATABASE | SCHEMA) [IF NOT EXISTS] schemaName;
DROP (DATABASE | SCHEMA) [IF EXISTS] schemaName;
Example:
CREATE DATABASE sharding_db;
DROP SCHEMA sharding_db;
[Proxy] How to use the right tool to connect to DBPlusEngine-Proxy when using DBPlusEngine-Proxy? #
Answer:
- DBPlusEngine-Proxy can be seen as a database server, so support for SQL command connections and operations is preferred.
- If other third party database tools are used, exceptions may occur due to the specific implementation of the different tools.
- The third party database tools that have been tested so far are as follows
- Navicat: 11.1.13, 15.0.20.
- DataGrip: 2020.1, 2021.1 (turn on
introspect using JDBC metadataoption when using IDEA/DataGrip). - WorkBench: 8.0.25.
[Proxy] When connecting to DBPlus Engine-Proxy using a third party database tool such as Navicat, the connection fails if DBPlus Engine-Proxy does not create a Schema or does not add a Resource? #
Answer:
- The third party database tool sends some SQL query metadata when connecting to DBPlus Engine-Proxy. When DBPlus Engine-Proxy does not create a schema or add a resource, DBPlus Engine-Proxy cannot execute SQL.
- It is recommended to create the schema and resource first before using a third party database tool to connect.
- For more information about resources, please refer to them.Related introduction
[Sharding] Cloud not resolve placeholder … in string value … exception solution? #
Answer:
The line expression identifier can be used as ${...} or $->{...} but the former conflicts with Spring’s own property file placeholders, so it is recommended to use $->{...} for line expression identifiers in a Spring environment. .
[Sharding] Why does an inline expression return a floating point number? #
Answer:
The result of dividing integers in Java is an integer, but the Groovy syntax for inline expressions is different, where the result of dividing integers is a floating point number. To get the result of dividing an integer, which need to change A/B to A.intdiv(B).
[Sharding] If only part of the database is sharded and split, does it need to configure the tables that are not sharded and split in the sharding rule as well? #
Answer:
No need, DBPlusEngine will recognize it automatically.
[Sharding] SingleKeyTableShardingAlgorithm with generic Long specified, encountered ClassCastException: Integer can not cast to Long?
#
Answer:
Must ensure that the field in the database table and the sharding algorithm are the same for that field type, e.g. if the field type in the database is int(11), the sharding type corresponding to the generic type should be Integer. If needed to configure it as a Long type, ensure that the field type in the database is bigint.
[Sharding, PROXY] When implementing the StandardShardingAlgorithm custom algorithm, a ClassCastException: Integer can not cast to Long occurs when the specific type of the Comparable is specified as Long and the field type in the database table is bigint.
#
Answer:
When implementing the doSharding method, it is not recommended to specify the specific type of Comparable in the method declaration, but rather to convert the type to the doSharding method implementation, see ModShardingAlgorithm#doSharding method
[Sharding] Why is the default distributed self-incrementing primary key policy provided by DBPlusEngine non-contiguous and mostly even-tailed? #
Answer:
DBPlusEngine uses the snowflake algorithm as the default distributed self-incrementing primary key strategy, which is used to ensure that non-repeating self-incrementing sequences can be generated without centralisation in a distributed context. Thus the self-incrementing primary key is guaranteed to be incremental, but not contiguous.
In contrast, the last 4 bits of the snowflake algorithm are accessed incrementally within the same millisecond. Therefore, if concurrency is not high within a millisecond, there is a high chance that the last 4 bits will be zero. Therefore applications with low concurrency will have a higher chance of generating an even primary key.
In version 3.1.0, the problem of mostly even trailing numbers has been completely solved, see: https://github.com/apache/shardingsphere/issues/1617
[Sharding] How to allow range query operations (BETWEEN AND, >, <, >=, <=) when inline table splitting policy? #
Answer:
- Version 4.1.0 or higher is required.
- Adjust the following configuration items (note that at this point all range queries will query each sub-table using a broadcast):
- Version 4.x:
allow.range.query.with.inline.shardingcan be set to true (default is false). - Version 5.x: just set
allow-range-query-with-inline-shardingto true in the InlineShardingStrategy (default is false).
[Sharding] Why does custom distributed primary keys not work even though having implemented the KeyGenerateAlgorithm interface and configured the Type?
#
Answer:
Service Provider Interface (SPI) is an API designed to be implemented or extended by third parties. In addition to implementing the interface, you need to create a corresponding file in META-INF/services to specify the SPI implementation classes before the JVM loads these services.
For details on how to use the SPI, please do your own search.
In the same way as the distributed primary key KeyGenerateAlgorithm interface, other DBPlusEngine extensionsneed to be injected in the same way to take effect.
[Sharding] Can DBPlusEngine support native self-incrementing primary keys in addition to the distributed primary keys that come with it? #
Answer:
Yes, it can be supported. However, there is a restriction on the use of the native self-incrementing primary key, i.e. you can not use the native self-incrementing primary key as a shard key at the same time.
As DBPlusEngine does not know the table structure of the database and the native self-incrementing primary key is not included in the original SQL, DBPlusEngine cannot resolve the field as a sharded field. If the incremented primary key is not a sharded key, it is not a concern and can be returned normally; if the incremented primary key is also used as a sharded key, DBPlusEngine can not resolve its sharded value, resulting in SQL routing to multiple tables, which affects the correctness of the application.
The prerequisite for a native incremented primary key return is that the INSERT SQL must eventually be routed to a single table, so an incremented primary key will return zero for an INSERT SQL that returns multiple tables.
[Data Encryption] JPA and Data Encryption don’t work together. How to fix it? #
Answer:
As the DDL for data encryption has not yet been developed, the use of JPA with data encryption for automatic DDL statement generation can result in a situation where the entity class (Entity) of the JPA cannot satisfy both the DDL and DML.
The solution is as follows:
- Write the JPA’s entity class with the name of the logical column that needs to be encrypted.
- Turn off auto-ddl for JPA, e.g. auto-ddl=none.
- Create the table manually, using the
cipherColumn,plainColumnandassistedQueryColumninstead of the logical columns in the data encryption configuration.
[Data Encryption] DESC Only logical columns can be seen in an encrypted table. Why do I get an error when I add a column with the same name as an encrypted column, plaintext column, or derived column through Proxy? #
DESC t_user;
+-------------------+--------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------------------+--------------+------+-----+-------------------+-----------------------------+
| user_id | int(11) | NO | PRI | NULL | auto_increment |
| user_name | varchar(64) | NO | | NULL | |
+-------------------+--------------+------+-----+-------------------+-----------------------------+
8 rows in set (0.09 sec)
mysql> ALTER TABLE t_user ADD COLUMN user_id_cipher varchar(255) DEFAULT null;
ERROR 1060 (42S21): Duplicate column name 'user_id_cipher'
Answer:
Since the metadata simulated by Proxy will only display logical columns, physical columns such as encrypted columns and derived columns will be automatically blocked in the table structure and uniformly modified to display logical columns. Therefore, when executing DDL through Proxy to add a column with the same name as a physical column such as an encrypted column, the execution will fail.
[DistSQL] How to set custom Driver connection parameters or connection pool properties when adding a data source using DistSQL? #
Answer:
- If you need to customize the Driver parameters, please define the
dataSourceusing theurlSourcemethod. - ShardingSphere preconfigures the necessary connection pool parameters such as
maxPoolSize,idleTimeout, etc. If you want to add or override parameters, please specify them in thedataSourceviaPROPERTIES. - The above rules are described in the related introduction
[DistSQL] Resource [xxx] is still used by [SingleTableRule] when using DistSQL to delete a resource.
#
Answer:
Resources referenced by the rule will not be deleted
If the resource is only referenced by a single table rule and the user confirms that the restriction can be ignored, then the optional parameter ignoring single tables can be added to force the deletion
[DistSQL] Failed to get driver instance for jdbcURL=xxx when adding resources with DistSQL.
#
Answer:
DBPlusEngine-Proxy did not add the jdbc driver during deployment, you need to put the jdbc driver into the ext-lib directory after DBPlusEngine-Proxy is unpacked, for example: mysql-connector.
[Other] How to debug if SQL is not executing correctly in DBPlusEngine? #
Answer:
The sql.show configuration is available in DBPlus Engine-Proxy and DBPlus Engine-Driver versions 1.5.0 onwards, which prints the full details of the parsing context and rewritten SQL and the final data source it is routed to in the info log.
The sql.show configuration is disabled by default and should be enabled by configuration if required.
Note: From version 5.x onwards, the
sql.showparameter has been changed tosql-show.
[Other] Why to get a compile error when reading the source code? IDEA does not index the generated code? #
Answer:
DBPlusEngine uses lombok to implement minimalist code. For more details on usage and installation, please refer to the lombok official website
The code under the org.apache.shardingsphere.sql.parser.autogen package is generated by ANTLR and can be quickly generated by executing the following command:
./mvnw -Dcheckstyle.skip=true -Drat.skip=true -Dmaven.javadoc.skip=true -Djacoco.skip=true -DskipITs -DskipTests install -T1C
Generated code such as org.apache.shardingsphere.sql.parser.autogen.PostgreSQLStatementParser Java files may not be indexed by the default configuration of IDEA due to the large size of the file.
You can adjust the IDEA property: idea.max.intellisense.filesize=10000
[Other] Do aggregated columns without aliases throw exceptions when using SQLSever and PostgreSQL? #
Answer:
SQLServer and PostgreSQL get aggregated columns without aliasing to rename them. For example, the following SQL:
SELECT SUM(num), SUM(num2) FROM tablexxx;
SQLServer gets the empty string and (2) columns, PostgreSQL gets the empty sum and sum(2) columns. This will cause ShardingSphere to fail to find the appropriate column when the results are merged together and an error will occur.
The correct way to write SQL should be:
SELECT SUM(num) AS sum_num, SUM(num2) AS sum_num2 FROM tablexxx;
[Other] Oracle Database Order By statement using Timestamp type throws exception “Order by value must implements Comparable”? #
Answer:
There are two ways to solve the above problem:
- configure the startup JVM with the parameter “-oracle.jdbc.J2EE13Compliant=true”
- set it by code during project initialization System.getProperties(). setProperty(“oracle.jdbc.J2EE13Compliant”, “true”).
The reason is as follows.
org.apache.shardingsphere.sharding.merge.dql.orderby.OrderByValue#getOrderValues() method is as follows.
private List<Comparable<?>> getOrderValues() throws SQLException {
List<Comparable<?>> result = new ArrayList<>(orderByItems.size());
for (OrderItem each : orderByItems) {
Object value = resultSet.getObject(each.getIndex());
Preconditions.checkState(null == value || value instanceof Comparable, "Order by value must implements Comparable");
result.add((Comparable<?>) value);
}
return result;
}
The resultSet.getObject(int index) method is used, for TimeStamp oracle will determine whether to return java.sql.TimeStamp or custom oralce.sql.TimeStamp based on the oracle.jdbc.J2EE13Compliant property. TIMESTAMP See the ojdbc source code oracle.jdbc.driver.TimestampAccessor#getObject(int var1) method for details.
Object getObject(int var1) throws SQLException {
Object var2 = null;
if(this.rowSpaceIndicator == null) {
DatabaseError.throwSqlException(21);
}
if(this.rowSpaceIndicator[this.indicatorIndex + var1] != -1) {
if(this.externalType != 0) {
switch(this.externalType) {
case 93:
return this.getTimestamp(var1);
default:
DatabaseError.throwSqlException(4);
return null;
}
}
if(this.statement.connection.j2ee13Compliant) {
var2 = this.getTimestamp(var1);
} else {
var2 = this.getTIMESTAMP(var1);
}
}
return var2;
}
[Other] Why is the file name too long when I clone DBPlusEngine source code via Git on Windows? #
Answer:
To keep the source code readable, the DBPlusEngine coding specification requires that classes, methods, and variables be named as they should be, avoiding abbreviations, which may result in some of the source code files being named long. Since the Windows version of Git is compiled using msys, it uses an older version of the Windows Api that limits file names to 260 characters.
The solution is as follows:
Open cmd.exe (you’ll need to add git to your environment variables) and run the following command to make git support long filenames:
git config --global core.longpaths true
In the case of Windows 10, the operating system’s filename length restriction also needs to be lifted via the registry or Group Policy (a reboot is required):
In the Registry Editor, create HKLM\SYSTEM\CurrentControlSet\Control\FileSystem LongPathsEnabled, type REG_DWORD, and set it to 1. Alternatively, from the System menu, click on the Settings icon and type “Edit Group Policy “Then in the window that opens, go to Computer Management > Administrative Templates > System > File System. Go to “File System” and double click on “Enable win32 long path” on the right hand side.
Reference: https://docs.microsoft.com/zh-cn/windows/desktop/FileIO/naming-a-file https://ourcodeworld.com/articles/read/109/how-to-solve-filename-too-long-error-in-git-powershell-and-github-application-for-windows
[Other] How to solve Type is required exception? #
Answer:
Many feature implementation classes in DBPlusEngine are loaded by way of SPI injection, such as distributed primary keys, registries, etc.; these features find the corresponding SPI implementation by type in the configuration, so the type must be specified in the configuration file.
[Other] How to speed up the metadata loading when the service is started?
#
Answer:
- Upgrade to version
4.0.1or higher to improve the loading speed of the metadata. - Refer to the connection pool you are using and turn the
- configuration item
max.connections.size.per.query(default is 1) to a higher value (version >= 3.0.0.M3 and lower than 5.0.0). - The configuration item
max-connections-size-per-query(default value 1) is turned up (version >= 5.0.0).
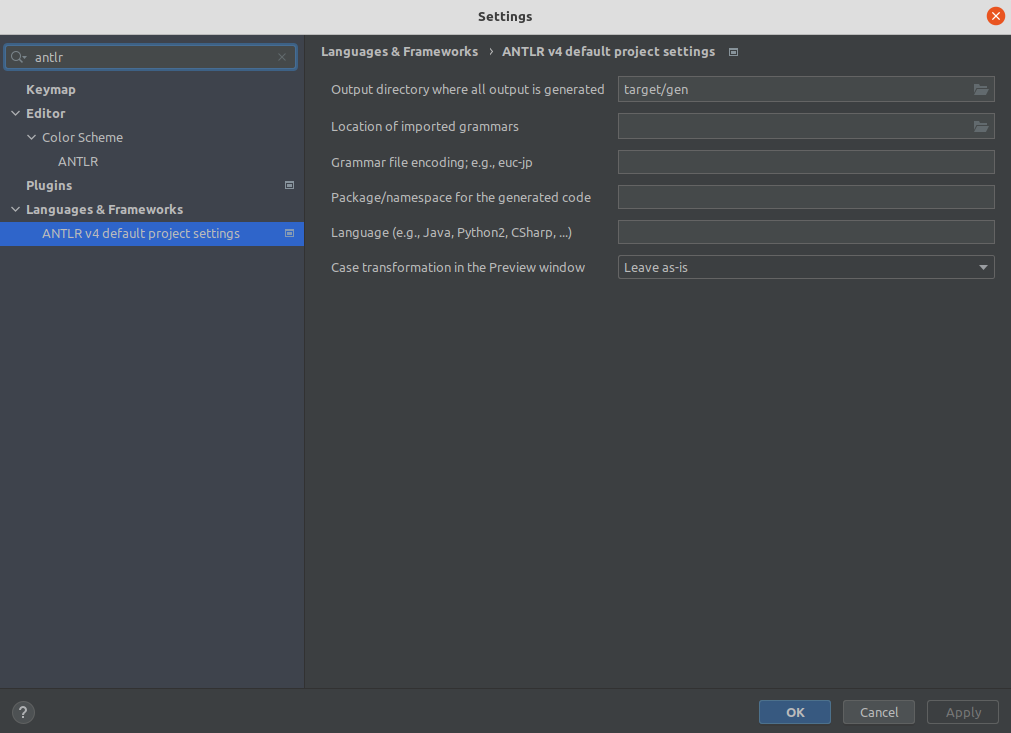
[Other] ANTLR plugin generates code in src sibling directory, it is easy to commit by mistake. How to avoid it? #
Answer:
Go to Settings Settings -> Languages & Frameworks -> ANTLR v4 default project settings configure the output directory for the generated code as target/gen, as illustrated in:
[Other] Incorrect database results when using Proxool?
#
Answer:
When using Proxool with multiple data sources, you should set an alias for each data source, because Proxool will determine if the connection pool contains an existing alias when it gets a connection, and not configuring alias will result in only getting a connection from one data source at a time.
The following is the key code of the getConnection method of the ProxoolDataSource class in the Proxool source code:
if(!ConnectionPoolManager.getInstance().isPoolExists(this.alias)) {
this.registerPool();
}
For more information on how to use alias, please refer to the Proxool Official website。
PS: The sourceforge website requires a wall to access.
[Other] When using Spring Boot 2.x to integrate DBPlusEngine, the property settings in the configuration file do not take effect? #
Answer:
In particular, note that the attribute name constraint in the configuration file for Spring Boot 2.x environments allows only lowercase letters, numbers and short horizontal lines, i.e. [a-z] [0-9] and -.
The reason for this is as follows.
In the Spring Boot 2.x environment, DBPlusEngine binds the configuration file via the Binder, and an irregular property name (e.g., camel or underscore, etc.) will cause the property setting to be invalid and thus throw a NullPointerException when verifying the property value. Refer to the following error example:
Underscore example: database_inline
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.props.algorithm-expression=ds-$->{user_id % 2}
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'database_inline': Initialization of bean failed; nested exception is java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
...
Caused by: java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
at com.google.common.base.Preconditions.checkNotNull(Preconditions.java:897)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.getAlgorithmExpression(InlineShardingAlgorithm.java:58)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.init(InlineShardingAlgorithm.java:52)
at org.apache.shardingsphere.spring.boot.registry.AbstractAlgorithmProvidedBeanRegistry.postProcessAfterInitialization(AbstractAlgorithmProvidedBeanRegistry.java:98)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsAfterInitialization(AbstractAutowireCapableBeanFactory.java:431)
...
Hump example: databaseInline
spring.shardingsphere.rules.sharding.sharding-algorithms.databaseInline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.databaseInline.props.algorithm-expression=ds-$->{user_id % 2}
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'databaseInline': Initialization of bean failed; nested exception is java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
...
Caused by: java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
at com.google.common.base.Preconditions.checkNotNull(Preconditions.java:897)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.getAlgorithmExpression(InlineShardingAlgorithm.java:58)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.init(InlineShardingAlgorithm.java:52)
at org.apache.shardingsphere.spring.boot.registry.AbstractAlgorithmProvidedBeanRegistry.postProcessAfterInitialization(AbstractAlgorithmProvidedBeanRegistry.java:98)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsAfterInitialization(AbstractAutowireCapableBeanFactory.java:431)
...
Analysis of the exception stack shows that: the AbstractAlgorithmProvidedBeanRegistry.registerBean method calls the PropertyUtil.containPropertyPrefix(environment, prefix) method to determine whether the configuration with the specified prefix, and the PropertyUtil.containPropertyPrefix(environment, prefix) method, which uses a Binder in a Spring Boot 2.x environment, will not work if the property name is not standardized (e.g., humped or underscored, etc.).