Explanation #
The current data migration solution uses a completely new database cluster as the migration target.
This implementation has the following advantages:
- No impact on the original data during migration.
- No risk in case of migration failure.
- Free from sharding policy limitations.
The implementation has the following disadvantages:
- Redundant servers can exist for a certain period of time.
- All data needs to be moved.
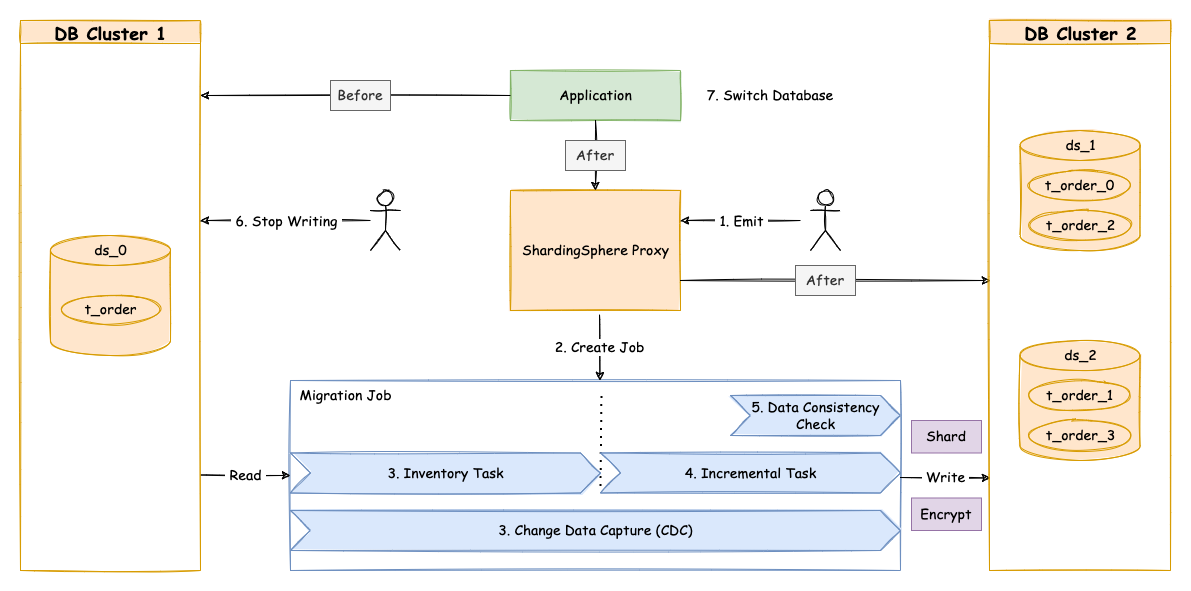
A single data migration mainly consists of the following phases:
- Preparation.
- Stock data migration.
- The synchronization of incremental data.
- Traffic switching .
Execution Stage Explained #
Preparation #
In the preparation stage, the data migration module verifies data source connectivity and permissions, counts stock data statistics, records the log and finally shards the tasks according to data volume and parallelism set by the users.
Stock data migration #
Execute the stock data migration tasks that have been sharded during preparation stage. The stock migration stage uses JDBC queries to read data directly from the source and write into the target based on the sharding rules and other configurations.
The Synchronization of incremental data #
Since the duration of stock data migration depends on factors such as data volume and parallelism, it is necessary to synchronize the data added to the business operations during this period. Different databases differ in technical details, but in general they are all based on replication protocols or WAL logs to achieve the capture of changed data.
- MySQL: subscribe and parse binlog
- PostgreSQL: uses official logical replication test_decoding.
These incremental data captured are also written into the new data nodes by the data migration modules. When synchronization of incremental data is basically completed (the incremental data flow is not interrupted since the business system is still in function), you can then move to the traffic switching stage.
Traffic Switching #
During this stage, there may be a read-only period of time, where data in the source data nodes is allowed to be in static mode for a short period of time to ensure that the incremental synchronization can be fully completed. Users can set this by shifting the database to read-only status or by controlling the traffic flow generated from the source.
The length of this read-only window depends on whether users need to perform consistency checks on the data and the exact amount of data in this scenario. Consistency check is an independent task. It supports separate start/stop and breakpoint resume.
Once confirmed, the data migration is complete. Users can then switch the read traffic or write traffic to Apache ShardingSphere.