FAQ #
[Driver] Why there may be an error when configuring both shardingsphere-jdbc-spring-boot-starter and a spring-boot-starter of certain datasource pool(such as druid)? #
Answer:
- Because the spring-boot-starter of certain datasource pool (such as druid) will be configured before shardingsphere-jdbc-spring-boot-starter and create a default datasource, then conflict occur when DBPlusEngine-Driver create datasources.
- A simple way to solve this issue is removing the spring-boot-starter of certain datasource pool, shardingsphere-jdbc create datasources with suitable pools.
[Driver] Why is xsd unable to be found when Spring Namespace is used? #
Answer:
The use norm of Spring Namespace does not require to deploy xsd files to the official website. But considering some users’ needs, we will deploy them to DBPlusEngine’s official website.
Actually, META-INF\spring.schemas in the jar package of shardingsphere-jdbc-spring-namespace has been configured with the position of xsd files:
META-INF\namespace\sharding.xsd and META-INF\namespace\replica-query.xsd, so you only need to make sure that the file is in the jar package.
[Driver] Found a JtaTransactionManager in spring boot project when integrating with transaction of XA #
Answer:
shardingsphere-transaction-xa-coreinclude atomikos, it will trigger auto-configuration mechanism in spring-boot, add@SpringBootApplication(exclude = JtaAutoConfiguration.class)will solve it.
[Proxy] In a Windows environment, I could not find or load main class org.apache.shardingsphere.proxy.Bootstrap, how to solve it? #
Answer:
Some decompression tools may truncate the file name when decompressing the DBPlusEngine-Proxy binary package, resulting in some classes not being found.
The solutions:
Open cmd.exe and execute the following command:
tar zxvf apache-shardingsphere-${RELEASE.VERSION}-shardingsphere-proxy-bin.tar.gz
[Proxy] How to add a new logic schema dynamically when using DBPlusEngine-Proxy? #
Answer:
When using DBPlusEngine-Proxy, users can dynamically create or drop logic schema through DistSQL, the syntax is as follows:
CREATE (DATABASE | SCHEMA) [IF NOT EXISTS] schemaName;
DROP (DATABASE | SCHEMA) [IF EXISTS] schemaName;
Example:
CREATE DATABASE sharding_db;
DROP SCHEMA sharding_db;
[Proxy] How to use suitable database tools when connecting DBPlusEngine-Proxy? #
Answer:
- DBPlusEngine-Proxy could be considered as a mysql sever, so we recommend using mysql command line tool to connect to and operate it.
- If users would like use a third-party database tool, there may be some errors cause of the certain implementation/options.
- The currently tested third-party database tools are as follows:
- Navicat:11.1.13、15.0.20.
- DataGrip:2020.1、2021.1 (turn on “introspect using jdbc metadata” in idea or datagrip).
- WorkBench:8.0.25.
[Proxy] When using a client such as Navicat to connect to DBPlusEngine-Proxy, if DBPlusEngine-Proxy does not create a Schema or does not add a Resource, the client connection will fail? #
Answer:
- Third-party database tools will send some SQL query metadata when connecting to DBPlusEngine-Proxy. When DBPlusEngine-Proxy does not create a
schemaor does not add aresource, DBPlusEngine-Proxy cannot execute SQL. - It is recommended to create
schemaandresourcefirst, and then use third-party database tools to connect. - Please refer to Related introduction the details about
resource.
[Sharding] How to solve Cloud not resolve placeholder … in string value … error?
#
Answer:
${...} or $->{...} can be used in inline expression identifiers, but the former one clashes with place holders in Spring property files, so $->{...} is recommended to be used in Spring as inline expression identifiers.
[Sharding] Why does float number appear in the return result of inline expression? #
Answer:
The division result of Java integers is also integer, but in Groovy syntax of inline expression, the division result of integers is float number. To obtain integer division result, A/B needs to be modified as A.intdiv(B).
[Sharding] If sharding database is partial, should tables without sharding database & table configured in sharding rules? #
Answer:
No, DBPlusEngine will recognize it automatically.
[Sharding] When generic Long type SingleKeyTableShardingAlgorithm is used, why doesClassCastException: Integer can not cast to Long exception appear?
#
Answer:
You must make sure the field in database table consistent with that in sharding algorithms. For example, the field type in database is int(11) and the sharding type corresponds to genetic type is Integer, if you want to configure Long type, please make sure the field type in the database is bigint.
[Sharding\PROXY] When implementing the StandardShardingAlgorithm custom algorithm, the specific type of Comparable is specified as Long, and the field type in the database table is bigint, a ClassCastException: Integer can not cast to Long exception occurs.
#
Answer:
When implementing the doSharding method, it is not recommended to specify the specific type of Comparable in the method declaration, but to convert the type in the implementation of the doSharding method. You can refer to the ModShardingAlgorithm#doSharding method.
[Sharding] Why are the default distributed auto-augment key strategy provided by DBPlusEngine not continuous and most of them end with even numbers? #
Answer:
ShardingSphere uses snowflake algorithms as the default distributed auto-augment key strategy to make sure unrepeated and decentralized auto-augment sequence is generated under the distributed situations. Therefore, auto-augment keys can be incremental but not continuous.
But the last four numbers of snowflake algorithm are incremental value within one millisecond. Thus, if concurrency degree in one millisecond is not high, the last four numbers are likely to be zero, which explains why the rate of even end number is higher.
In 3.1.0 version, the problem of ending with even numbers has been totally solved, please refer to: https://github.com/apache/shardingsphere/issues/1617
[Sharding] How to allow range query with using inline sharding strategy(BETWEEN AND, >, <, >=, <=)? #
Answer:
- Update to 4.1.0 above.
- Configure(A tip here: then each range query will be broadcast to every sharding table):
- Version 4.x:
allow.range.query.with.inline.shardingtotrue(Default value isfalse). - Version 5.x:
allow-range-query-with-inline-shardingtotruein InlineShardingStrategy (Default value isfalse).
[Sharding] Why does my custom distributed primary key do not work after implementing KeyGenerateAlgorithm interface and configuring type property?
#
Answer:
Service Provider Interface (SPI) is a kind of API for the third party to implement or expand. Except implementing interface, you also need to create a corresponding file in META-INF/services to make the JVM load these SPI implementations.
More detail for SPI usage, please search by yourself.
Other DBPlusEngine functionality implementation will take effect in the same way.
[Sharding] In addition to internal distributed primary key, does ShardingSphere support other native auto-increment keys? #
Answer:
Yes. But there is restriction to the use of native auto-increment keys, which means they cannot be used as sharding keys at the same time.
Since DBPlusEngine does not have the database table structure and native auto-increment key is not included in original SQL, it cannot parse that field to the sharding field. If the auto-increment key is not sharding key, it can be returned normally and is needless to be cared. But if the auto-increment key is also used as sharding key, DBPlusEngine cannot parse its sharding value, which will make SQL routed to multiple tables and influence the rightness of the application.
The premise for returning native auto-increment key is that INSERT SQL is eventually routed to one table. Therefore, auto-increment key will return zero when INSERT SQL returns multiple tables.
[Encryption] How to solve that data encryption can’t work with JPA?
#
Answer:
Because DDL for data encryption has not yet finished, JPA Entity cannot meet the DDL and DML at the same time, when JPA that automatically generates DDL is used with data encryption.
The solutions are as follows:
- Create JPA Entity with logicColumn which needs to encrypt.
- Disable JPA auto-ddl, For example setting auto-ddl=none.
- Create table manually. Table structure should use
cipherColumn,plainColumnandassistedQueryColumnto replace the logicColumn.
[DistSQL] How to set custom JDBC connection properties or connection pool properties when adding a data source using DistSQL? #
Answer:
- If you need to customize JDBC connection properties, please take the
urlSourceway to definedataSource. - DBPlusEngine presets necessary connection pool properties, such as
maxPoolSize,idleTimeout, etc. If you need to add or overwrite the properties, please specify it withPROPERTIESin thedataSource. - Please refer to Related introduction for above rules.
[DistSQL] How to solve Resource [xxx] is still used by [SingleTableRule]. exception when dropping a data source using DistSQL?
#
Answer:
Resources referenced by rules cannot be deleted
If the resource is only referenced by single table rule, and the user confirms that the restriction can be ignored, the optional parameter ignore single tables can be added to perform forced deletion
UNREGISTER STORAGE UNIT dataSourceName [, dataSourceName] ... [ignore single tables]
[DistSQL] How to solve Failed to get driver instance for jdbcURL=xxx. exception when adding a data source using DistSQL?
#
Answer:
DBPlusEngine Proxy do not have jdbc driver during deployment. Some example of this include mysql-connector. To use it otherwise following syntax can be used:
REGISTER STORAGE UNIT dataSourceName [..., dataSourceName]
[Other] How to debug when SQL can not be executed rightly in DBPlusEngine? #
Answer:
sql.show configuration is provided in DBPlusEngine-Proxy and post-1.5.0 version of DBPlusEngine-Driver, enabling the context parsing, rewritten SQL and the routed data source printed to info log. sql.show configuration is off in default, and users can turn it on in configurations.
A Tip: Property sql.show has changed to sql-show in version 5.x.
[Other] Why do some compiling errors appear? Why did not the IDEA index the generated codes? #
Answer:
DBPlusEngine uses lombok to enable minimal coding. For more details about using and installment, please refer to the official website of lombok.
The codes under the package org.apache.shardingsphere.sql.parser.autogen are generated by ANTLR. You may execute the following command to generate codes:
./mvnw -Dcheckstyle.skip=true -Drat.skip=true -Dmaven.javadoc.skip=true -Djacoco.skip=true -DskipITs -DskipTests install -T1C
The generated codes such as org.apache.shardingsphere.sql.parser.autogen.PostgreSQLStatementParser may be too large to be indexed by the IDEA.
You may configure the IDEA’s property idea.max.intellisense.filesize=10000.
[Other] In SQLSever and PostgreSQL, why does the aggregation column without alias throw exception? #
Answer:
SQLServer and PostgreSQL will rename aggregation columns acquired without alias, such as the following SQL:
SELECT SUM(num), SUM(num2) FROM tablexxx;
Columns acquired by SQLServer are empty string and (2); columns acquired by PostgreSQL are empty sum and sum(2). It will cause error because DBPlusEngine is unable to find the corresponding column.
The right SQL should be written as:
SELECT SUM(num) AS sum_num, SUM(num2) AS sum_num2 FROM tablexxx;
[Other] Why does Oracle database throw “Order by value must implements Comparable” exception when using Timestamp Order By? #
Answer:
There are two solutions for the above problem: 1. Configure JVM parameter “-oracle.jdbc.J2EE13Compliant=true” 2. Set System.getProperties().setProperty(“oracle.jdbc.J2EE13Compliant”, “true”) codes in the initialization of the project.
Reasons:
org.apache.shardingsphere.sharding.merge.dql.orderby.OrderByValue#getOrderValues():
private List<Comparable<?>> getOrderValues() throws SQLException {
List<Comparable<?>> result = new ArrayList<>(orderByItems.size());
for (OrderByItem each : orderByItems) {
Object value = queryResult.getValue(each.getIndex(), Object.class);
Preconditions.checkState(null == value || value instanceof Comparable, "Order by value must implements Comparable");
result.add((Comparable<?>) value);
}
return result;
}
After using resultSet.getObject(int index), for TimeStamp oracle, the system will decide whether to return java.sql.TimeStamp or define oralce.sql.TIMESTAMP according to the property of oracle.jdbc.J2EE13Compliant. See oracle.jdbc.driver.TimestampAccessor#getObject(int var1) method in ojdbc codes for more detail:
Object getObject(int var1) throws SQLException {
Object var2 = null;
if(this.rowSpaceIndicator == null) {
DatabaseError.throwSqlException(21);
}
if(this.rowSpaceIndicator[this.indicatorIndex + var1] != -1) {
if(this.externalType != 0) {
switch(this.externalType) {
case 93:
return this.getTimestamp(var1);
default:
DatabaseError.throwSqlException(4);
return null;
}
}
if(this.statement.connection.j2ee13Compliant) {
var2 = this.getTimestamp(var1);
} else {
var2 = this.getTIMESTAMP(var1);
}
}
return var2;
}
[Other] In Windows environment,when cloning DBPlusEngine source code through Git, why prompt filename too long and how to solve it? #
Answer:
To ensure the readability of source code,the DBPlusEngine Coding Specification requires that the naming of classes,methods and variables be literal and avoid abbreviations,which may result in Some source files have long names.
Since the Git version of Windows is compiled using msys,it uses the old version of Windows Api,limiting the file name to no more than 260 characters.
The solutions are as follows:
Open cmd.exe (you need to add git to environment variables) and execute the following command to allow git supporting log paths:
git config --global core.longpaths true
If we use windows 10, also need enable win32 log paths in registry editor or group strategy(need reboot):
Create the registry key
HKLM\SYSTEM\CurrentControlSet\Control\FileSystem LongPathsEnabled(Type: REG_DWORD) in registry editor, and be set to 1. Or click “setting” button in system menu, print “Group Policy” to open a new window “Edit Group Policy”, and then click ‘Computer Configuration’ > ‘Administrative Templates’ > ‘System’ > ‘Filesystem’, and then turn on ‘Enable Win32 long paths’ option.
Reference material:
https://docs.microsoft.com/zh-cn/windows/desktop/FileIO/naming-a-file https://ourcodeworld.com/articles/read/109/how-to-solve-filename-too-long-error-in-git-powershell-and-github-application-for-windows
[Other] How to solve Type is required error?
#
Answer:
In DBPlusEngine, many functionality implementation are uploaded through SPI, such as Distributed Primary Key. These functions load SPI implementation by configuring the type,so the type must be specified in the configuration file.
[Other] How to speed up the metadata loading when service starts up? #
Answer:
- Update to 4.0.1 above, which helps speed up the process of loading table metadata.
- Configure:
max.connections.size.per.query(Default value is 1) higher referring to connection pool you adopt(Version >= 3.0.0.M3 & Version < 5.0.0).max-connections-size-per-query(Default value is 1) higher referring to connection pool you adopt(Version >= 5.0.0).
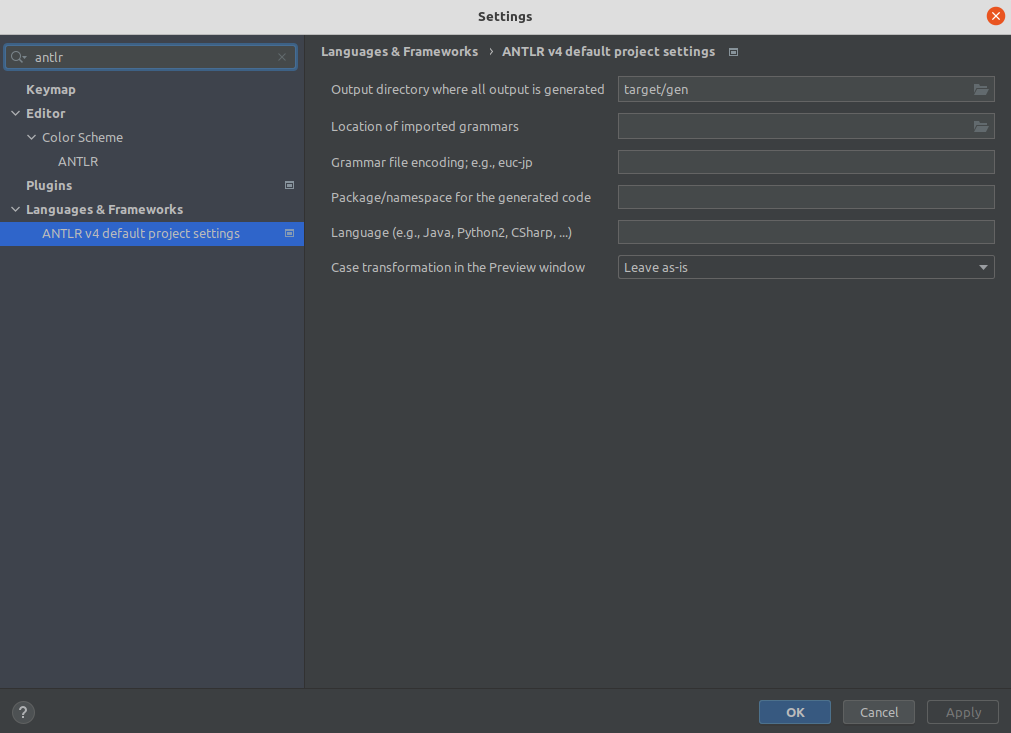
[Other] The ANTLR plugin generates codes in the same level directory as src, which is easy to commit by mistake. How to avoid it? #
Answer:
Goto Settings -> Languages & Frameworks -> ANTLR v4 default project settings and configure the output directory of the generated code as target/gen as shown:
[Other] Why is the database sharding result not correct when using Proxool?
#
Answer:
When using Proxool to configure multiple data sources, each one of them should be configured with alias. It is because Proxool would check whether existing alias is included in the connection pool or not when acquiring connections, so without alias, each connection will be acquired from the same data source.
The followings are core codes from ProxoolDataSource getConnection method in Proxool:
if(!ConnectionPoolManager.getInstance().isPoolExists(this.alias)) {
this.registerPool();
}
For more alias usages, please refer to Proxool official website.
[Other] The property settings in the configuration file do not take effect when integrating DBPlusEngine with Spring Boot 2.x ? #
Answer:
Note that the property name in the Spring Boot 2.x environment is constrained to allow only lowercase letters, numbers and short transverse lines, [a-z][0-9] and -.
Reasons:
In the Spring Boot 2.x environment, DBPlusEngine binds the properties through Binder, and the unsatisfied property name (such as camel case or underscore.) can throw a NullPointerException exception when the property setting does not work to check the property value. Refer to the following error examples:
Underscore case: database_inline
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.props.algorithm-expression=ds-$->{user_id % 2}
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'database_inline': Initialization of bean failed; nested exception is java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
...
Caused by: java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
at com.google.common.base.Preconditions.checkNotNull(Preconditions.java:897)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.getAlgorithmExpression(InlineShardingAlgorithm.java:58)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.init(InlineShardingAlgorithm.java:52)
at org.apache.shardingsphere.spring.boot.registry.AbstractAlgorithmProvidedBeanRegistry.postProcessAfterInitialization(AbstractAlgorithmProvidedBeanRegistry.java:98)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsAfterInitialization(AbstractAutowireCapableBeanFactory.java:431)
...
Camel case:databaseInline
spring.shardingsphere.rules.sharding.sharding-algorithms.databaseInline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.databaseInline.props.algorithm-expression=ds-$->{user_id % 2}
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'databaseInline': Initialization of bean failed; nested exception is java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
...
Caused by: java.lang.NullPointerException: Inline sharding algorithm expression cannot be null.
at com.google.common.base.Preconditions.checkNotNull(Preconditions.java:897)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.getAlgorithmExpression(InlineShardingAlgorithm.java:58)
at org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm.init(InlineShardingAlgorithm.java:52)
at org.apache.shardingsphere.spring.boot.registry.AbstractAlgorithmProvidedBeanRegistry.postProcessAfterInitialization(AbstractAlgorithmProvidedBeanRegistry.java:98)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsAfterInitialization(AbstractAutowireCapableBeanFactory.java:431)
...
From the exception stack, the AbstractAlgorithmProvidedBeanRegistry.registerBean method calls PropertyUtil.containPropertyPrefix (environment, prefix) , and PropertyUtil.containPropertyPrefix (environment, prefix) determines that the configuration of the specified prefix does not exist, while the method uses Binder in an unsatisfied property name (such as camelcase or underscore) causing property settings does not to take effect.