Auto Scaling on Cloud (HPA) #
Definition #
In Kubernetes, HorizontalPodAutoscaler(HPA) automatically updates workload resources to automatically scale workloads to meet requirements.
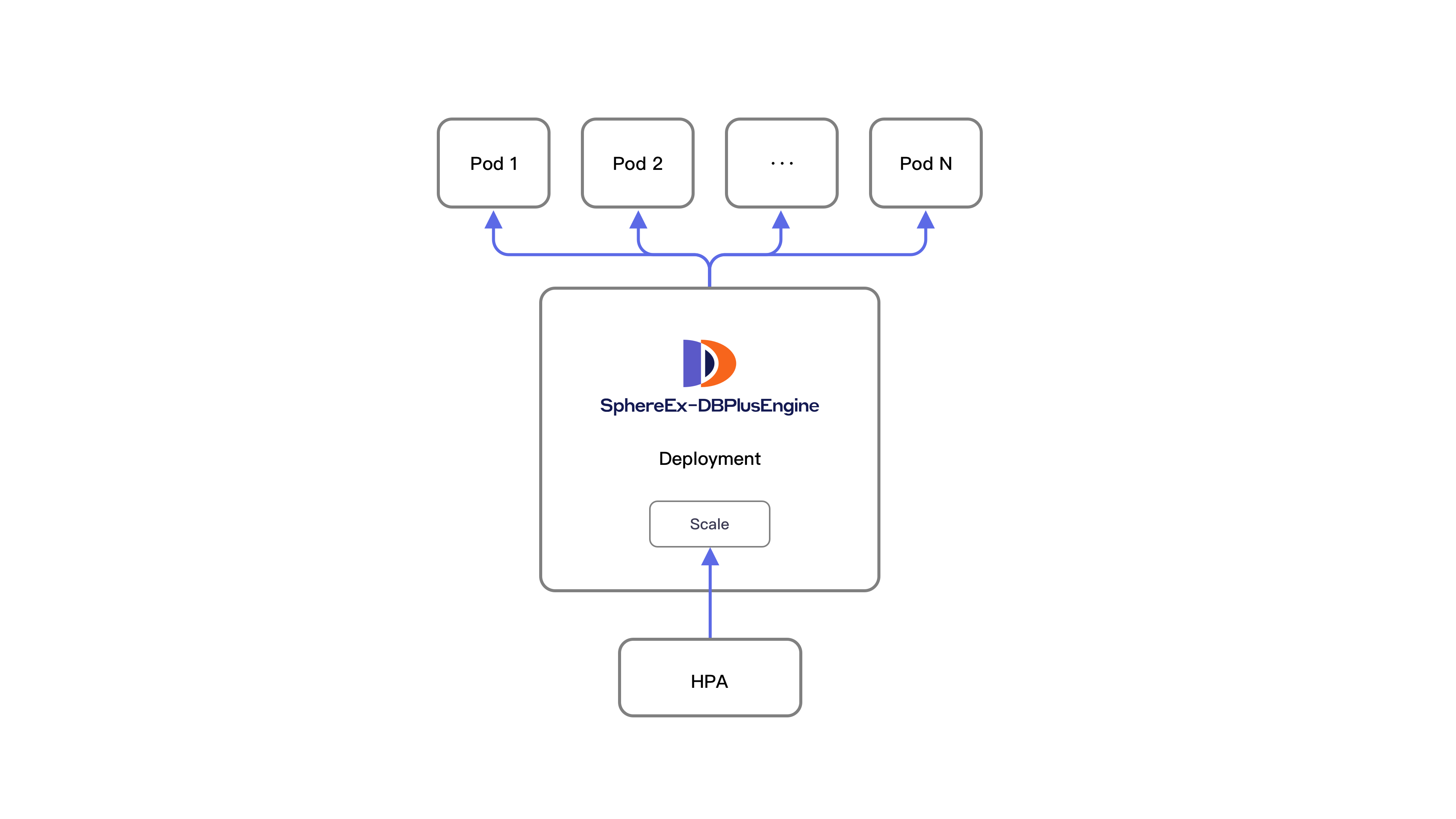
SphereEx-Operator uses the HPA feature in Kubernetes and combines the relevant indicators of SphereEx-DBPlusEngine to automatically scale the capacity during operation in the kubernetes cluster.
After the auto scaling feature is enabled, the SphereEx-Operator will apply an HPA object in the Kubernetes cluster while deploying a SphereEx-DBPlusEngine cluster.
Related Concepts #
HPA #
HPA (HorizontalPodAutoscaler) refers to that SphereEx-Operator uses the HPA function in Kubernetes to auto scale the capacity of SphereEx-DBPlusEngine cluster.
Impact on the System #
After auto scaling is enabled, manually setting the replica of SphereEx-DBPlusEngine in kubernetes will not take effect. The number of replicas of SphereEx-DBPlusEngine cluster is controlled by the maximum and minimum values of HPA controller, and elastic scaling will be processed between these two values.
The minimum number of starting copies of SphereEx-DBPlusEngine will also be controlled by the minimum number of copies of HPA. After the automatic scaling feature is turned on, SphereEx-DBPlusEngine will start with the minimum number of copies of HPA.
The scaling using HPA is the horizontal scaling of SphereEx-DBPlusEngine. Horizontal scaling means that the response to the increased load is to deploy more pods.
This is different from “vertical” scaling. For kubernetes, vertical scaling means allocating more resources (such as memory or CPU) to the pod that has been running for the workload.
Limitations #
At this stage, due to the insufficient indexes of SphereEx-DBPlusEngine, the stress load test can only be carried out through the runtime CPU. Other indicators will be added in the future to enrich the runtime pressure calculation method of SphereEx-DBPlusEngine.
If you want to use the HPA function of SphereEx-DBPlusEngine in Kubernetes, you need to install metrics-server in your cluster and be able to use kubectl top function normally.
While creating the SphereEx-DBPlusEngine cluster, the SphereEx-Operator will establish load balancing in front of the SphereEx-DBPlusEngine cluster. Your application and SphereEx-DBPlusEngine are linked through load balancing.
Because SphereEx-DBPlusEngine establishes long links with your application, it will not significantly reduce the load on the existing long links in the process of scaling-out. The effect of scaling-out will only take effect on the newly established links after scaling-out.
There will also be corresponding problems while scaling-in. In the process of scaling-in, your application will flash, because the reduced SphereEx-DBPlusEngine copy is in the process of scaling-in, it will be removed from the load balance, and the long link between your application and SphereEx-DBPlusEngine will also be destroyed.
How it works #
The scaling using HPA is the horizontal scaling of SphereEx-DBPlusEngine. Horizontal scaling means that the response to the increased load is to deploy more pods.
This is different from “vertical” scaling. For kubernetes, vertical scaling means allocating more resources (such as memory or CPU) to the pod that has been running for the workload.
If the load is reduced and the number of pods is higher than the configured minimum value, horizontalpodautoscaler will indicate that the workload resources (deployment, statefulset, or other similar resources) are reduced.
In the kubernetes cluster, a controller will query the indicators in the HPA created by related resources at a certain interval. After meeting the threshold of the indicator, the corresponding resources will be scaling-out or scaling-in according to the calculation formula.
In the working process of SphereEx-Operator, HPA object acts on the deployment object of SphereEx-DBPlusEngine, and continuously queries the CPU utilization of each copy of SphereEx-DBPlusEngine.
The CPU utilization of SphereEx-DBPlusEngine obtains the CPU usage from the container /sys/fs/cgroup/cpu/cpuacct.usage, and the value set in the automaticScaling.target field in the shardingsphere.sphere-ex.com/v1alpha1.proxy is used as the percentage of the threshold value for continuous calculation.
When the calculated value reaches the threshold, the HPA controller calculates the number of copies according to the following formula:
Expected number of copies = ceil[Current number of copies * (Current indicators / Expected indicators)]
It is worth noting that the CPU utilization index is the CPU value in the resources.requests field of each copy.
Before checking the tolerance and determining the final value, the control plane will also consider whether any indicators are missing and how many pod are ready.
When CPU metrics are used to scale, any pod that is not ready (still initializing, or may be unhealthy) or the latest indicator measure is collected in the pod before the ready state, the pod will also be shelved.
Schematic diagram: